강의
학습 페이지
www.inflearn.com
오늘은 Normal Mapping 과 Displacement Mapping에 대해 학습하고 예제코드를 분석해보자.
우선 Normal Mapping은 물체를 정밀하게 표현하기 위해서는 삼각형의 개수를 늘리는 방법도 있지만 이 방법은 너무 부하가 많아진다. 그렇기 때문에 삼각형의 개수를 늘리지 않고 물체 표면의 Normal 값을 조정해주는 것으로 물체의 표면을 정밀하게 표현한다.
이때 조정할 노멀 값을 모아서 노말 텍스처를 만들어주게 되는데 이때 텍스처에는 tagent Space 좌표계가 적용되어 있는데 이때 n(normal)값이 제일 많기 때문에 파란색으로 표현되곤 한다. 이 텍스처의 normal값을 추출해서 물체에 적용해주면 된다.
우선 코드를 실행시켜보면 왼쪽에는 Normal Mapping이 적용되지 않은 모습이고 오른쪽에는 Normal Mapping이 적용된 모습이다.
보통 노멀매핑은 24비트로 8비트씩 나눠서 3개의 좌표를 사용한다. 1바이트이기 때문에 각 값은 0~1사이의 값으로
표현한다. 이를 float -1~1까지의 값으로 치환해주는 공식을 통해 치환해주게 된다.
이때 tagent space라는 개념이 나오는데 이 정보는 매쉬의 정점에 포함된 정보로 이 좌표계를 기준으로 하는 x,y,z정보를 텍스처공간에 저장해주고 이 값을 통해 Normal Mapping을 해주는 것이다. 이때 정점 정보를 입력해줄 때 VertexIn 구조체의 정보와 같이 노멀정보와 탄젠트 정보를 넣어주어야한다.
예제 코드에서 쉐이더 부분을 살펴보자면 노멀 정보를 가져와서 월드좌표로 바꿔주는 부분이 함수로 만들어져있고 이를 PS단계에서 호출하여 사용해주고 있다.
struct VertexIn
{
float3 PosL : POSITION;
float3 NormalL : NORMAL;
float2 Tex : TEXCOORD;
float3 TangentL : TANGENT;
};
struct VertexOut
{
float4 PosH : SV_POSITION;
float3 PosW : POSITION;
float3 NormalW : NORMAL;
float3 TangentW : TANGENT;
float2 Tex : TEXCOORD;
};
VertexOut VS(VertexIn vin)
{
VertexOut vout;
// Transform to world space space.
vout.PosW = mul(float4(vin.PosL, 1.0f), gWorld).xyz;
vout.NormalW = mul(vin.NormalL, (float3x3)gWorldInvTranspose);
vout.TangentW = mul(vin.TangentL, (float3x3)gWorld);
// Transform to homogeneous clip space.
vout.PosH = mul(float4(vin.PosL, 1.0f), gWorldViewProj);
// Output vertex attributes for interpolation across triangle.
vout.Tex = mul(float4(vin.Tex, 0.0f, 1.0f), gTexTransform).xy;
return vout;
}
Texture2D gNormalMap;
float3 normalMapSample = gNormalMap.Sample(samLinear, pin.Tex).rgb;
float3 bumpedNormalW = NormalSampleToWorldSpace(normalMapSample, pin.NormalW, pin.TangentW);
월드좌표로 변환해줄 때 텍스처에서 UV좌표를 이용하여 특정 좌표를 구한다음에 그 값을 -1~1사이의 값으로 공식을 통해 변환해준 다음 월드좌표로 변환해주고 있다. 이때 이미 VS값에서 World를 구해줬지만 PS단계에서 보간때문에 normal과 tagent의 수직이 깨질 수 있기 때문에 이를 수정해주기 위해 탄젠트 값을 다시 연산을 해준 다음 탄젠트 스페이스에서 월드 스페이스로 변환해주고 있다.
//---------------------------------------------------------------------------------------
// Transforms a normal map sample to world space.
//---------------------------------------------------------------------------------------
float3 NormalSampleToWorldSpace(float3 normalMapSample, float3 unitNormalW, float3 tangentW)
{
// Uncompress each component from [0,1] to [-1,1].
float3 normalT = 2.0f * normalMapSample - 1.0f;
// Build orthonormal basis.
float3 N = unitNormalW;
float3 T = normalize(tangentW - dot(tangentW, N) * N);
float3 B = cross(N, T);
float3x3 TBN = float3x3(T, B, N);
// Transform from tangent space to world space.
float3 bumpedNormalW = mul(normalT, TBN);
return bumpedNormalW;
}
그리고 이렇게 변환된 값을 통해 빛연산을 해주고 있다.
// Sum the light contribution from each light source.
[unroll]
for (int i = 0; i < gLightCount; ++i)
{
float4 A, D, S;
ComputeDirectionalLight(gMaterial, gDirLights[i], bumpedNormalW, toEye,
A, D, S);
ambient += A;
diffuse += D;
spec += S;
}
litColor = texColor * (ambient + diffuse) + spec;
if (gReflectionEnabled)
{
float3 incident = -toEye;
float3 reflectionVector = reflect(incident, bumpedNormalW);
float4 reflectionColor = gCubeMap.Sample(samLinear, reflectionVector);
litColor += gMaterial.Reflect * reflectionColor;
}
다음은 Displacement Mapping 표면에 굴곡과 균열을 묘사하는 높이 값을 넘겨주고 이를 통해 기하구조를 변경하는 것이다. 구현은 노멀매핑에서 w값을 height로 사용하거나 따로 텍스처를 만들어주면 된다. 왼쪽이 Normal Mapping만 적용된 화면이고 오른쪽이 Displacement Mapping까지 적용된 모습이다.
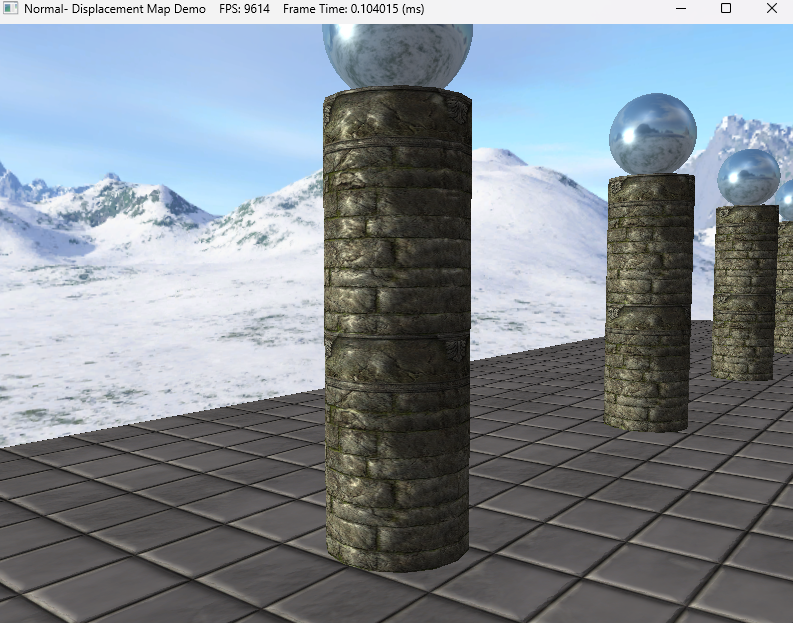
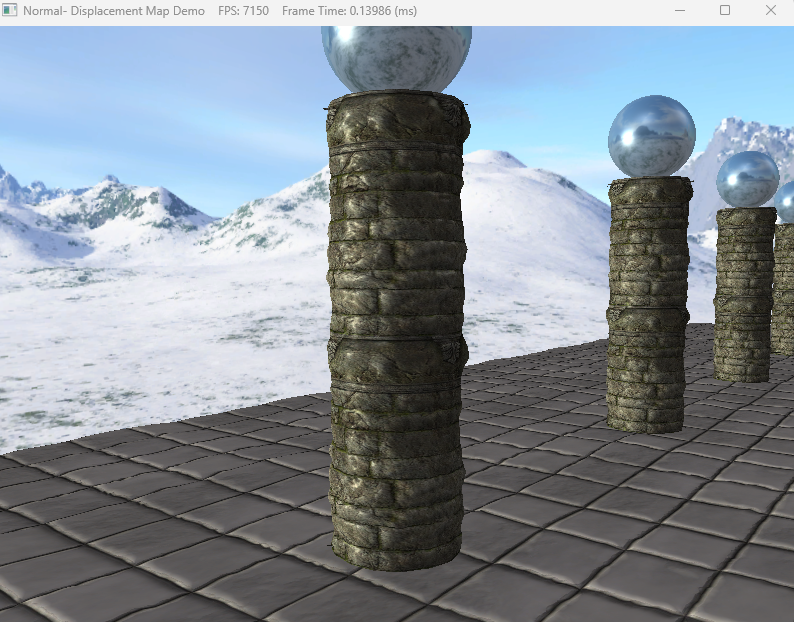
이 표면의 높이값을 실시간으로 조정해주기 위해서는 매쉬를 직접 조정해주는 방법도 있지만 이렇게 하면 부하가 심해지기 때문에 정점을 건드리지 않고 조정해줄 방법을 찾아야하는데 Tesellation 단계를 통해 조정을 해준다.
코드를 보면 예제에서는 노멀 텍스처w값을 추출해서 사용하는 것을 볼 수 있다.
Texture2D gNormalMap;
PatchTess PatchHS(InputPatch<VertexOut, 3> patch,
uint patchID : SV_PrimitiveID)
{
PatchTess pt;
// Average tess factors along edges, and pick an edge tess factor for
// the interior tessellation. It is important to do the tess factor
// calculation based on the edge properties so that edges shared by
// more than one triangle will have the same tessellation factor.
// Otherwise, gaps can appear.
pt.EdgeTess[0] = 0.5f * (patch[1].TessFactor + patch[2].TessFactor);
pt.EdgeTess[1] = 0.5f * (patch[2].TessFactor + patch[0].TessFactor);
pt.EdgeTess[2] = 0.5f * (patch[0].TessFactor + patch[1].TessFactor);
pt.InsideTess = pt.EdgeTess[0];
return pt;
}
struct HullOut
{
float3 PosW : POSITION;
float3 NormalW : NORMAL;
float3 TangentW : TANGENT;
float2 Tex : TEXCOORD;
};
[domain("tri")]
[partitioning("fractional_odd")]
[outputtopology("triangle_cw")]
[outputcontrolpoints(3)]
[patchconstantfunc("PatchHS")]
HullOut HS(InputPatch<VertexOut, 3> p,
uint i : SV_OutputControlPointID,
uint patchId : SV_PrimitiveID)
{
HullOut hout;
// Pass through shader.
hout.PosW = p[i].PosW;
hout.NormalW = p[i].NormalW;
hout.TangentW = p[i].TangentW;
hout.Tex = p[i].Tex;
return hout;
}
struct DomainOut
{
float4 PosH : SV_POSITION;
float3 PosW : POSITION;
float3 NormalW : NORMAL;
float3 TangentW : TANGENT;
float2 Tex : TEXCOORD;
};
//테셀레이션- 최종 위치결정
[domain("tri")]
DomainOut DS(PatchTess patchTess,
float3 bary : SV_DomainLocation,
const OutputPatch<HullOut, 3> tri)
{
DomainOut dout;
dout.PosW = bary.x * tri[0].PosW + bary.y * tri[1].PosW + bary.z * tri[2].PosW;
dout.NormalW = bary.x * tri[0].NormalW + bary.y * tri[1].NormalW + bary.z * tri[2].NormalW;
dout.TangentW = bary.x * tri[0].TangentW + bary.y * tri[1].TangentW + bary.z * tri[2].TangentW;
dout.Tex = bary.x * tri[0].Tex + bary.y * tri[1].Tex + bary.z * tri[2].Tex;
dout.NormalW = normalize(dout.NormalW);
const float MipInterval = 20.0f;
float mipLevel = clamp((distance(dout.PosW, gEyePosW) - MipInterval) / MipInterval, 0.0f, 6.0f);
//텍스처에서 height 추출
float h = gNormalMap.SampleLevel(samLinear, dout.Tex, mipLevel).a;
//포지션 조정
dout.PosW += (gHeightScale * (h - 1.0)) * dout.NormalW;
//포지션 조정
dout.PosH = mul(float4(dout.PosW, 1.0f), gViewProj);
return dout;
}'게임공부 > Directx11(물방울책)' 카테고리의 다른 글
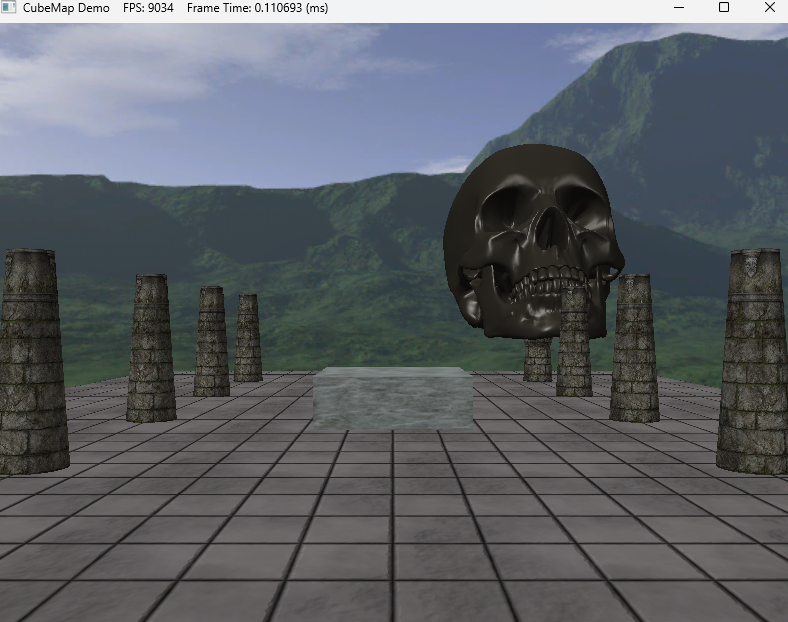
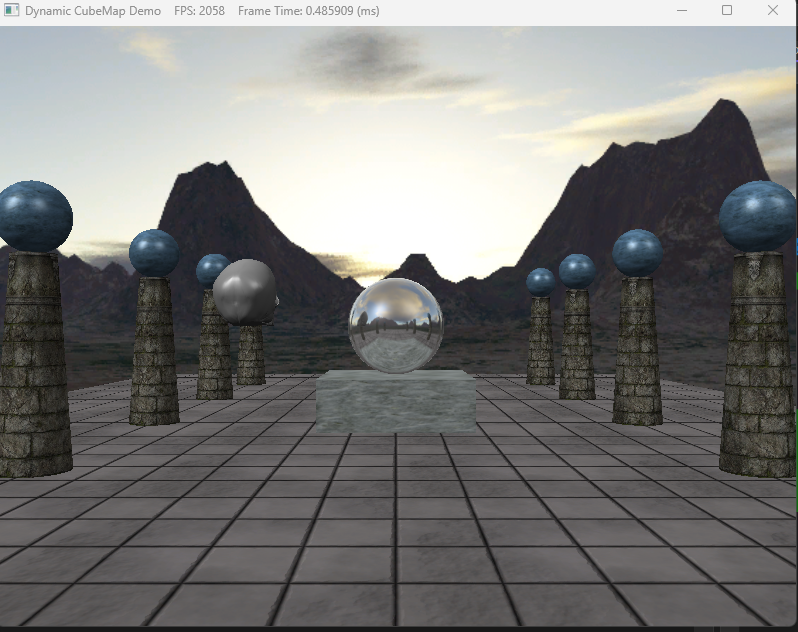
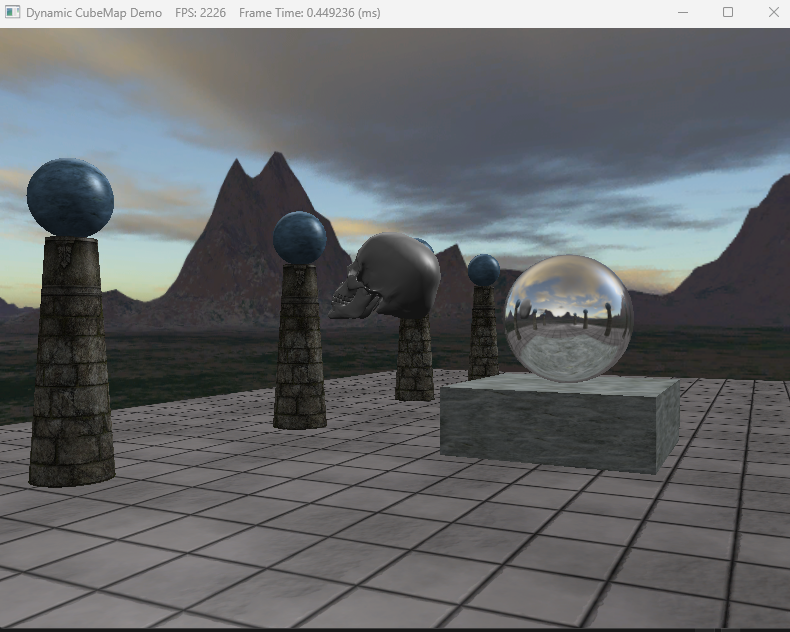
| [Directx11][C++][물방울]12. Cube Mapping (2) | 2024.11.01 |
|---|---|
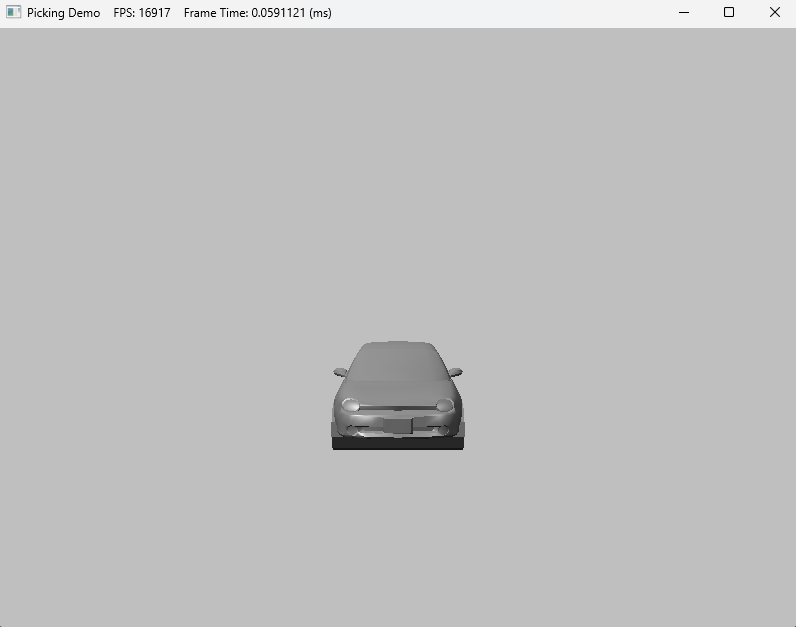
| [Directx11][C++][물방울]11. Picking (5) | 2024.10.31 |
| [Directx11][C++][물방울]10. Instancing and Culling (1) | 2024.10.30 |
| [Directx11][C++][물방울]9. Tessellation (5) | 2024.10.29 |
| [Directx11][C++][물방울]8. Compute Shader (0) | 2024.10.22 |