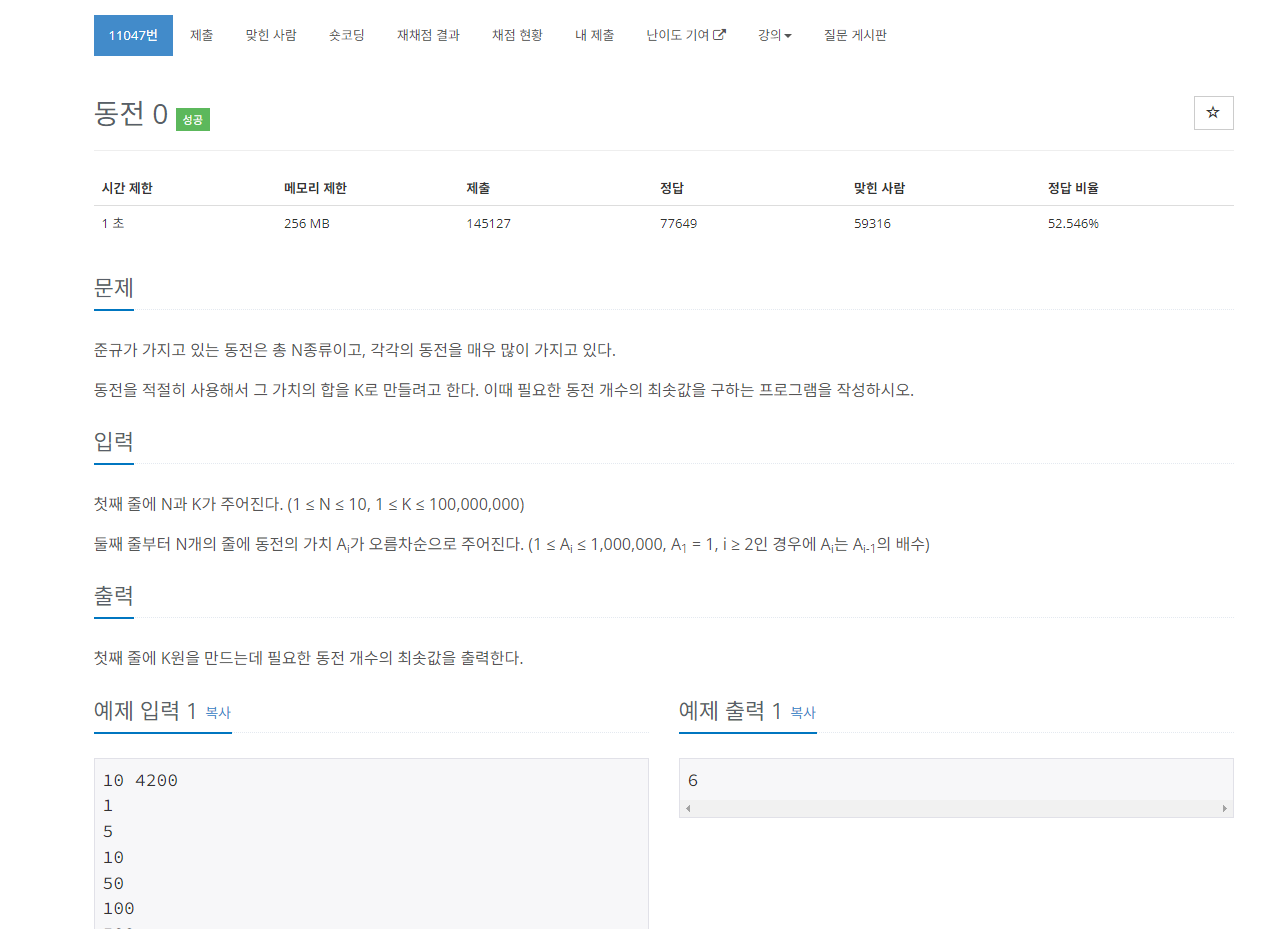
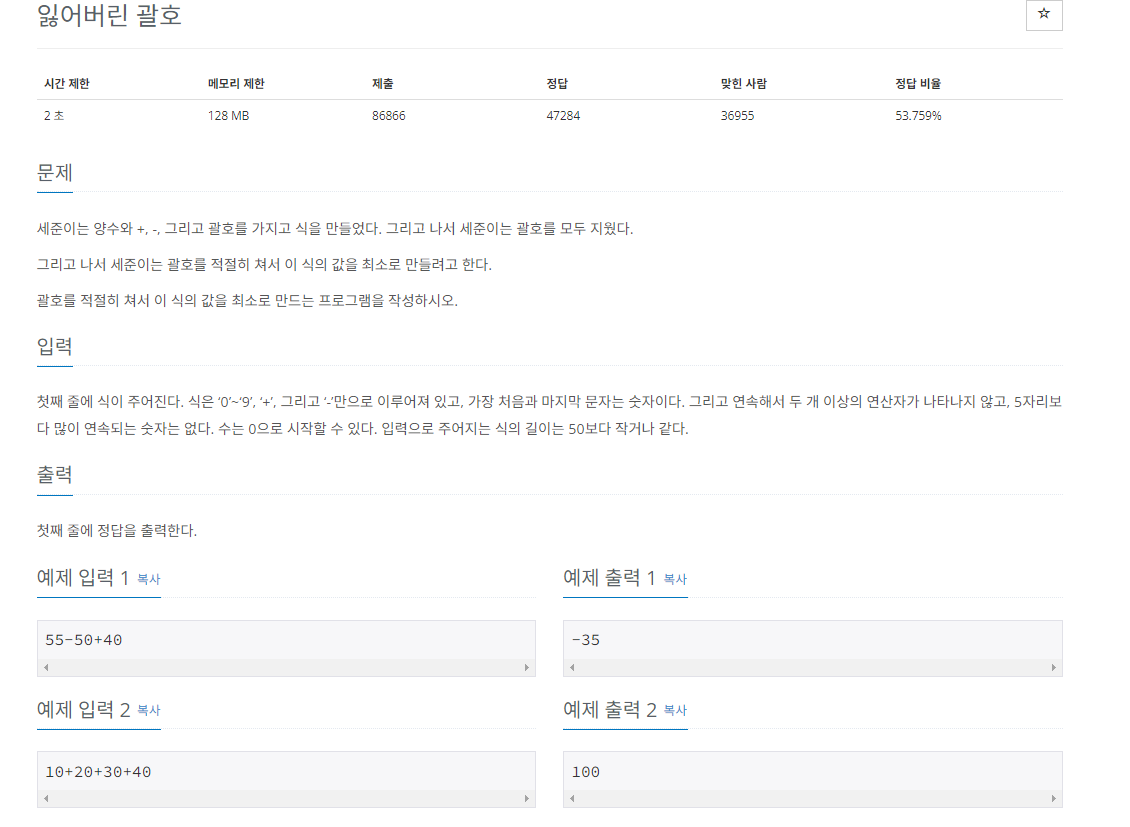
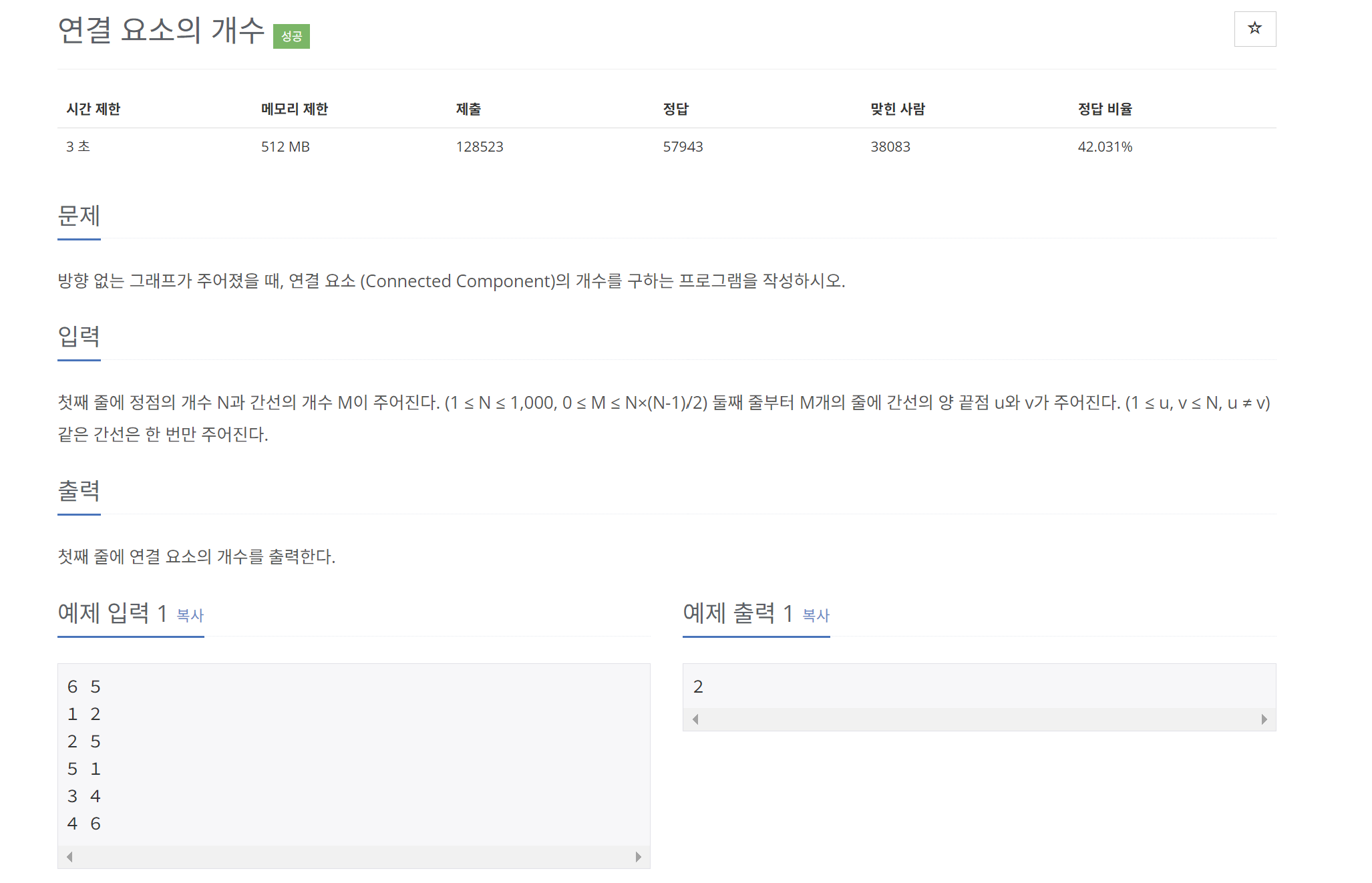
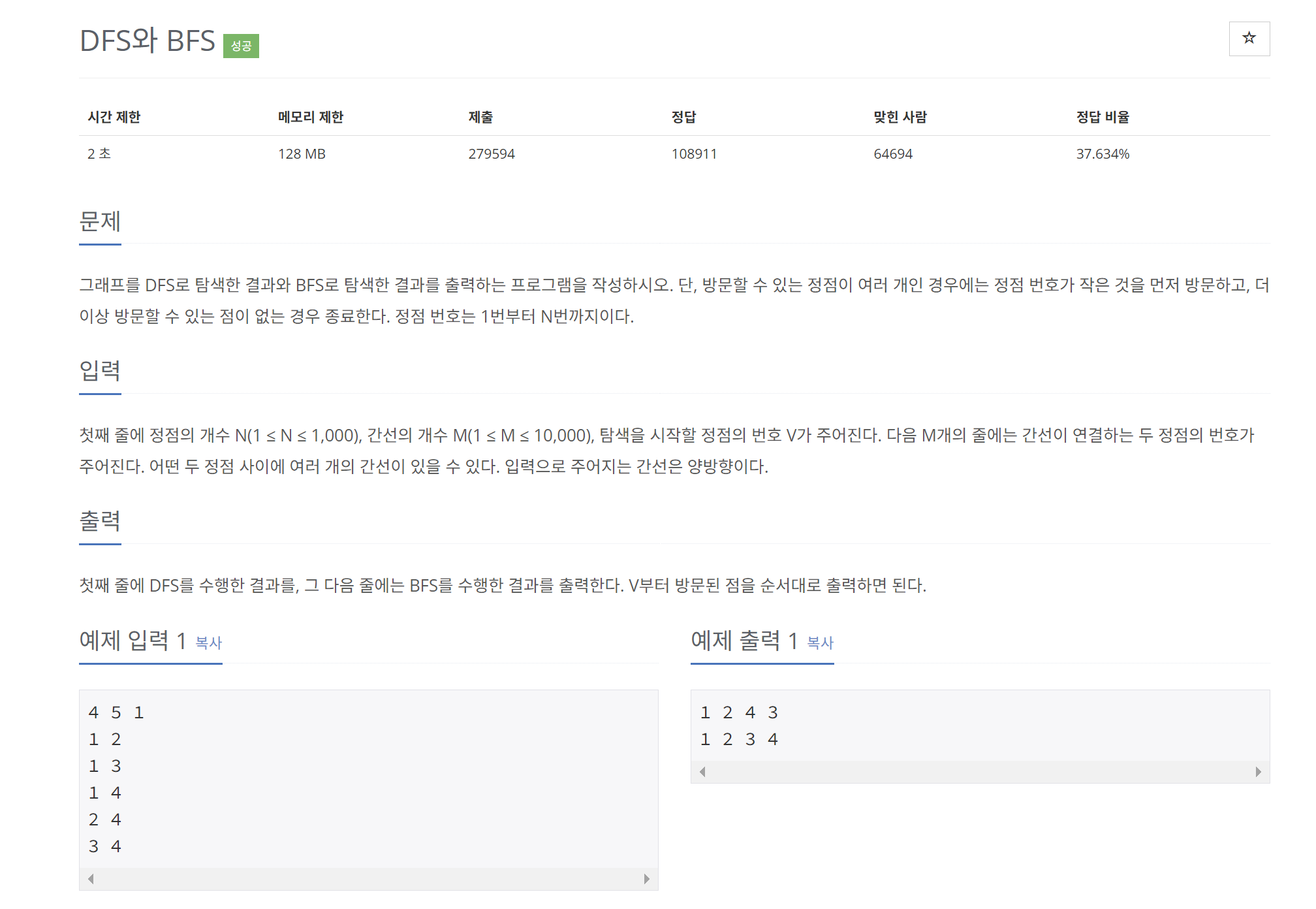
이번 문제도 문제설명이 길어서 잘 읽어야한다.
문제는 손님이 주문한 단품메뉴들을 가지고 가능한 조합을 모두 만든 다음
손님이 주문한 횟수만큼 해당 메뉴의 카운트를 증가 시켜주고
2명 이상이 주문한 메뉴 중에 코스에 들어갈 음식의 개수와 맞으면서가장 많이 선택된 음식이 조건에 부합한다면 저장해 주면 된다.
#include <string>
#include <vector>
#include <algorithm>
#include <unordered_map>
using namespace std;
unordered_map<string,int>m; //조합한 메뉴 저장할 맵
void dfs(int idx,string tmp,string order){
if(tmp.size()>order.size()){
return;
}
m[tmp]++;
for(int i=idx;i<order.size();i++){
dfs(i+1,tmp+order[i],order);
}
}
vector<string> solution(vector<string> orders, vector<int> course) {
vector<string> answer;
for(auto order : orders){
sort(order.begin(),order.end());
dfs(0,"",order); //조합할 수 있는 모든 메뉴 저장
}
for(auto cours : course){
int mostOrdered=0;
for(auto menu:m){
if(menu.first.size()==cours){ //코스의 개수를 만족하면서 가장 많이 선택된 횟수 선택
mostOrdered=max(mostOrdered,menu.second);
}
}
if(mostOrdered<=1)continue; //만약 2명 이상의 손님에게 주문된 구성이 아닐 때
for(auto menu : m){
if(menu.first.size()==cours&&menu.second==mostOrdered){
answer.push_back(menu.first); //조건에 부합한다면 저장
}
}
}
sort(answer.begin(),answer.end());
return answer;
}'코딩테스트 > 이론' 카테고리의 다른 글
| [코딩테스트][C++]이론6. 그리디 알고리즘 (0) | 2024.04.04 |
|---|---|
| [코딩테스트][C++]이론5. DFS 와 BFS (0) | 2024.03.29 |
| [코딩테스트][C++]이론4-2. 정렬 (2) | 2024.03.16 |
| [코딩테스트][C++]이론4-1. 정렬 (0) | 2024.03.15 |
| [코딩테스트][C++]이론3. 스택과 큐 (0) | 2024.03.14 |