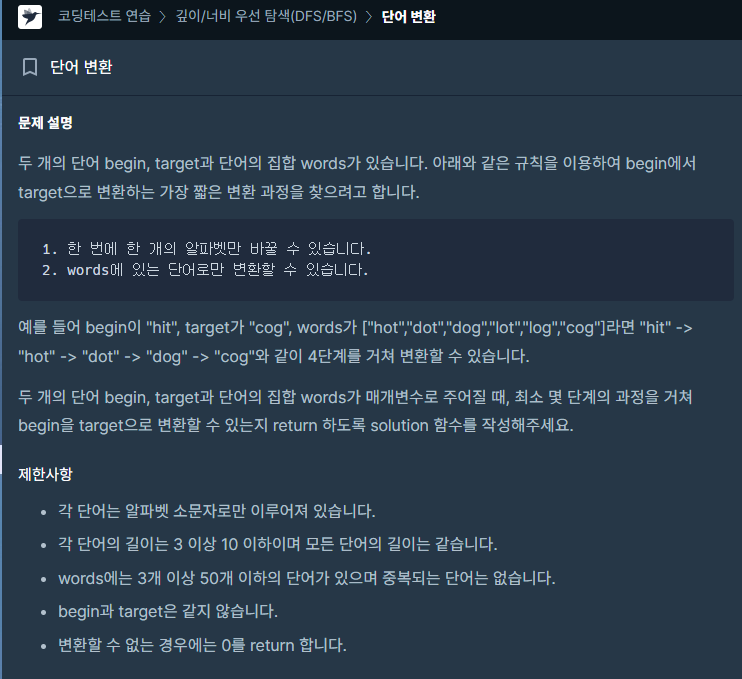
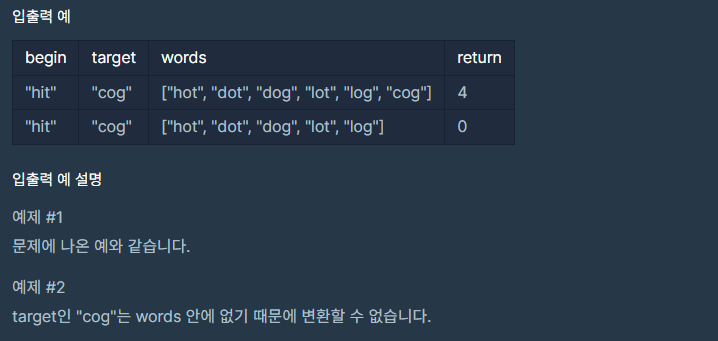
단어 배열에서 시작단어와 한 글자만 다른것을 찾아서 변환하고 최종단어까지 도달가능할때까지의 단계를 구하는 문제
한글자만 다른 것을 찾아가는 과정을 반복하는 것이라 DFS를 생각해보았다. 이 과정에서 한글자만 다른 것을 찾는게 함수 내부에 구현하기보다 따로 함수를 만들어주는 게 편해서 그렇게 해보았다.
그리고 가질 수 있는 최대의 단어개수보다 시도횟수가 많으면 안되고 다 순회했을 때도 답이 없을 경우엔 0을 return하게 해준다.
#include <string>
#include <vector>
#include <algorithm>
int answer = 50;
bool visited[50];
using namespace std;
bool diff_st(string a, string b) { //두 문자열 비교해서 다른 문자가 1개인지 판별
int diff = 0;
for (int i = 0; i < a.size(); i++) {
if (a[i] != b[i]) {
diff++;
}
}
if (diff == 1) {
return true;
}
else return false;
}
void dfs(string begin, string target, vector<string> words, int cnt) {
if (answer <= cnt) {
return;
}
if (begin == target) {
answer = min(answer, cnt); //answer은 최대길이 값보다 작은 것 중에 최소값
return;
}
for (int i = 0; i < words.size(); i++) {
if (diff_st(begin, words[i]) && !visited[i]) { //다른 문자가 한개라면
visited[i] = true;
dfs(words[i], target, words, cnt + 1);
visited[i] = false;
}
}
return;
}
int solution(string begin, string target, vector<string> words) {
dfs(begin, target, words, 0);
if (answer == 50) { //만약 모두를 탐색했는데도 target에 도달하지 못했을 경우
return 0;
}
return answer;
}'코딩테스트 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스][C++][LV2](DP)땅따먹기 (0) | 2024.02.01 |
|---|---|
| [프로그래머스 LV 2] 더 맵게 (0) | 2024.01.28 |
| [프로그래머스 LV 3](DFS) 여행경로 (0) | 2024.01.25 |
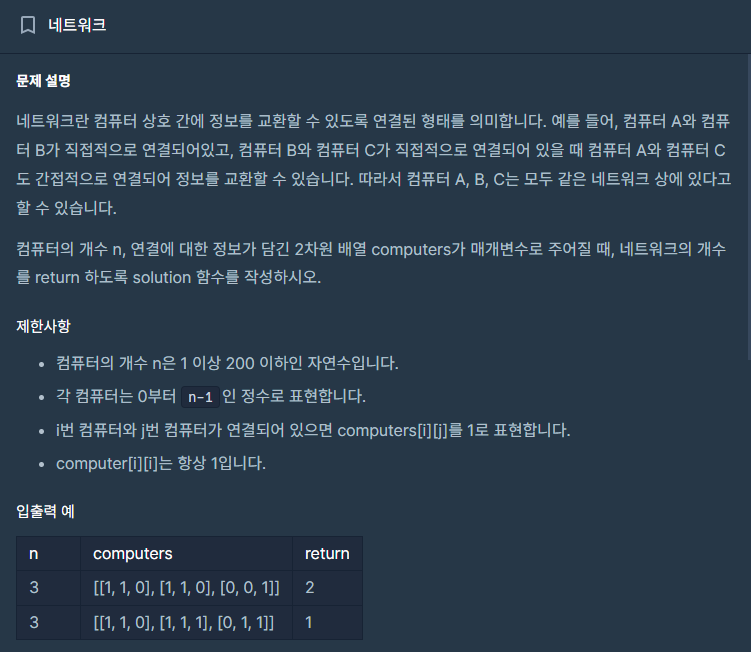
| [프로그래머스 LV 3](DFS)네트워크 (1) | 2024.01.25 |
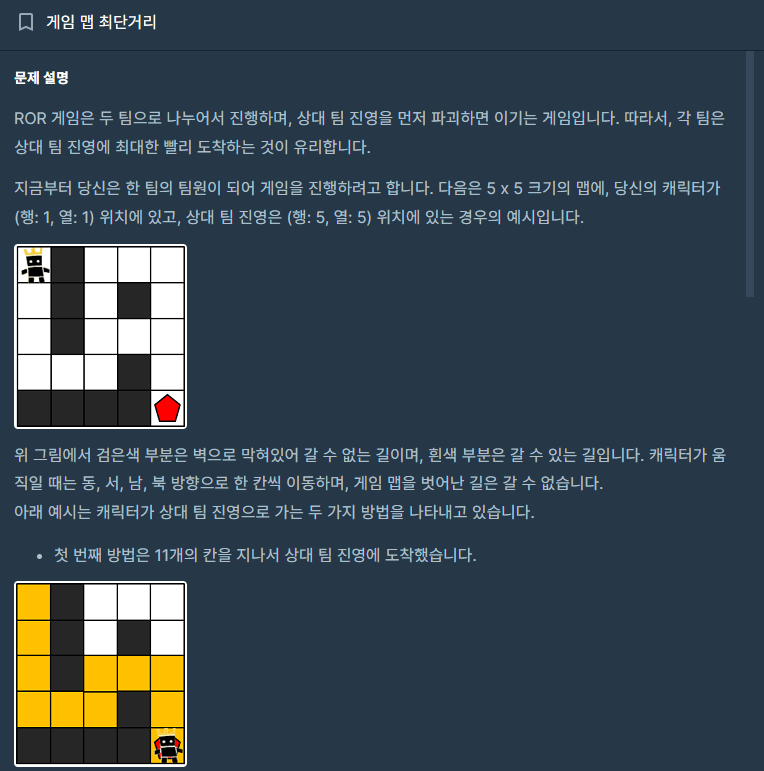
| [프로그래머스 LV 2] 게임 맵 최단거리 (0) | 2024.01.24 |