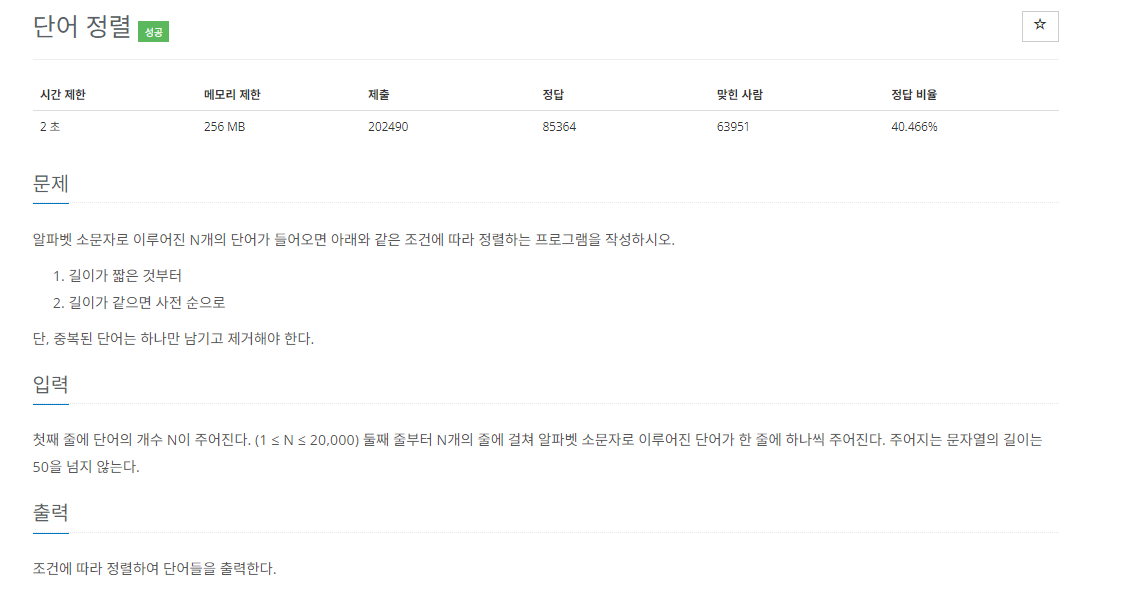
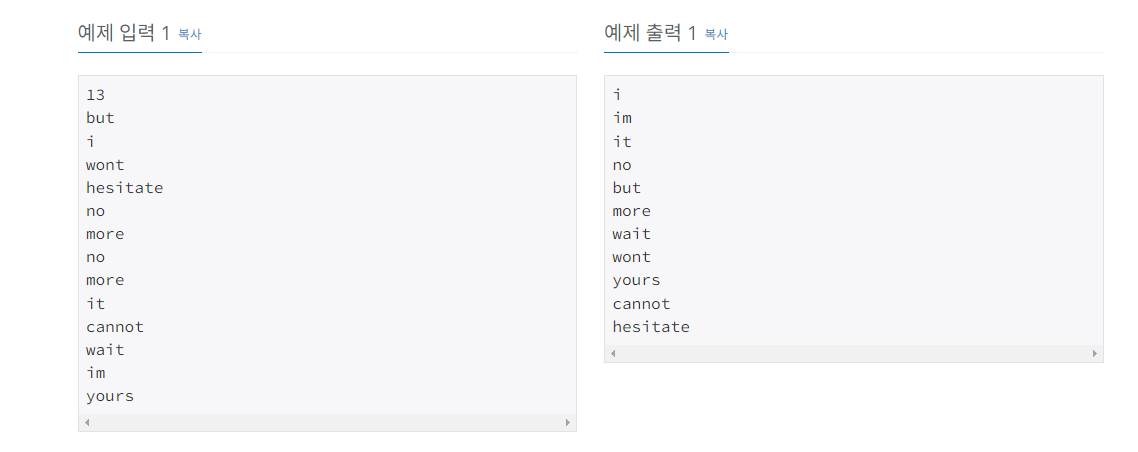
https://www.acmicpc.net/problem/1764


n개의 단어에서 나온 값과 m개의 단어에서 나온 값이 같은게 몇개인지 출력하고 해당하는 단어를 사전 순으로 출력해주면 되는 문제이다.
나는 map자료형을 통해 중복되는 단어를 vector에 저장하고 sort를 통해 사전순으로 정렬한 다음 해당 vector의 크기와
원소를 순서대로 출력해주었다.
정답코드
#include <iostream>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
unordered_map<string, bool>hear;
vector<string> both;
int main()
{
int n, m, cnt = 0;
cin >> n >> m;
for (int i = 0; i < n; i++)
{
string person;
cin >> person;
hear[person] = true;
}
for (int i = 0; i < m; i++)
{
string person;
cin >> person;
if (hear[person])
{
both.push_back(person);
}
}
// 사전 순으로 정렬
sort(both.begin(), both.end());
cout << both.size() << '\n';
for (const auto& name : both) {
cout << name << '\n';
}
return 0;
}'코딩테스트 > 백준' 카테고리의 다른 글
| [백준][C++]11478번. 서로 다른 부분 문자열의 개수 (0) | 2024.10.01 |
|---|---|
| [백준][C++]1269번. 대칭 차집합 (6) | 2024.09.30 |
| [백준][C++]1620번. 나는야 포켓몬 마스터 이다솜 (3) | 2024.09.27 |
| [백준][C++]7785번. 회사에 있는 사람 (4) | 2024.09.26 |
| [백준][C++]14425번. 문자열 집합 (1) | 2024.09.26 |