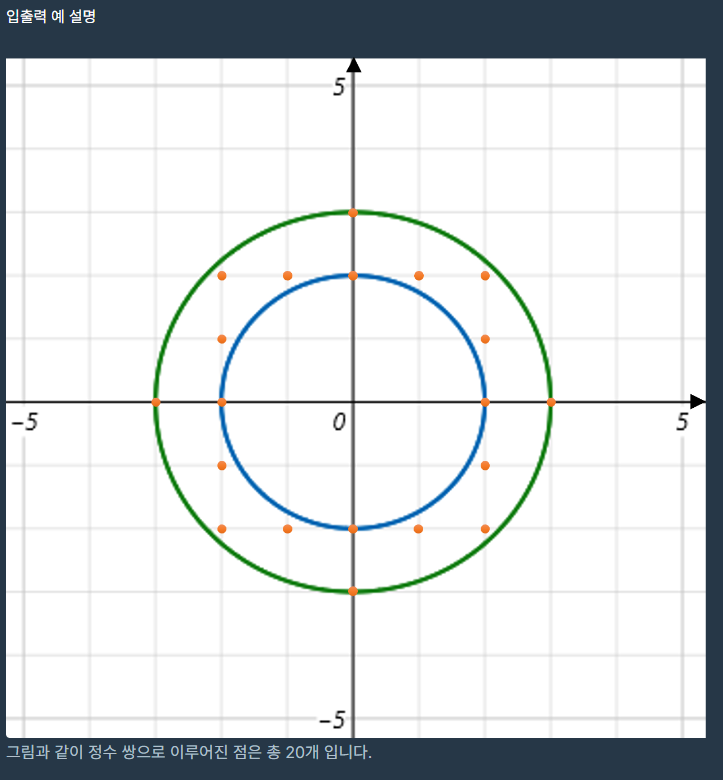
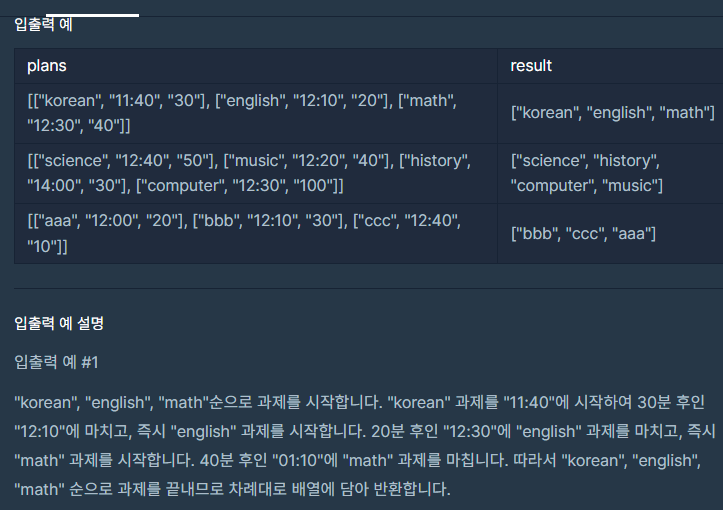
https://school.programmers.co.kr/learn/courses/30/lessons/42890
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

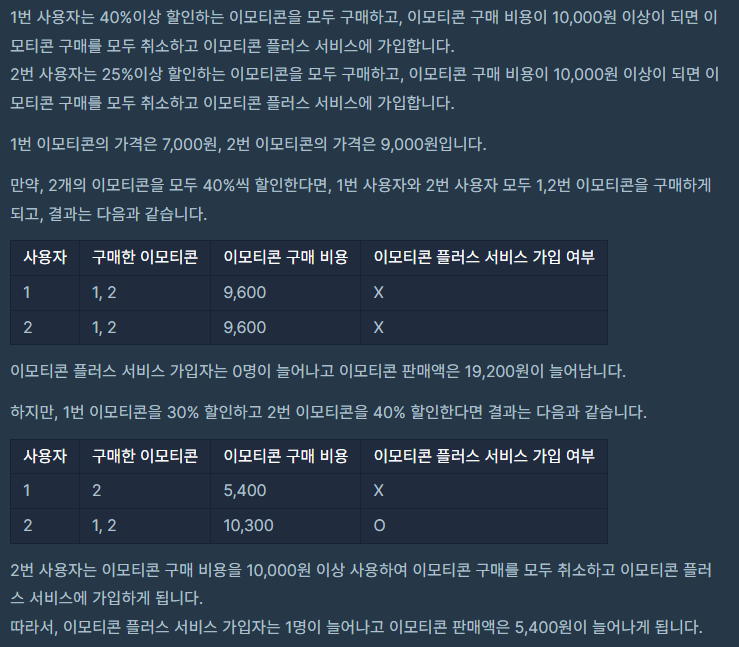
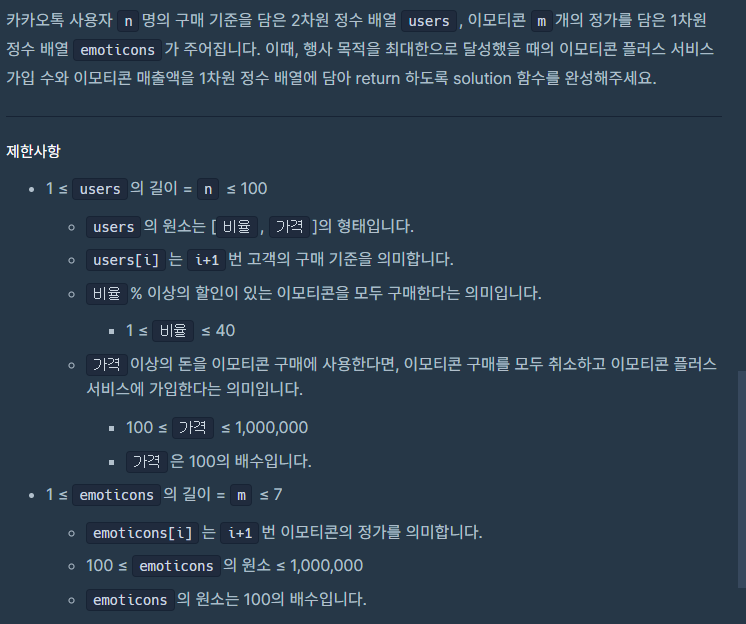
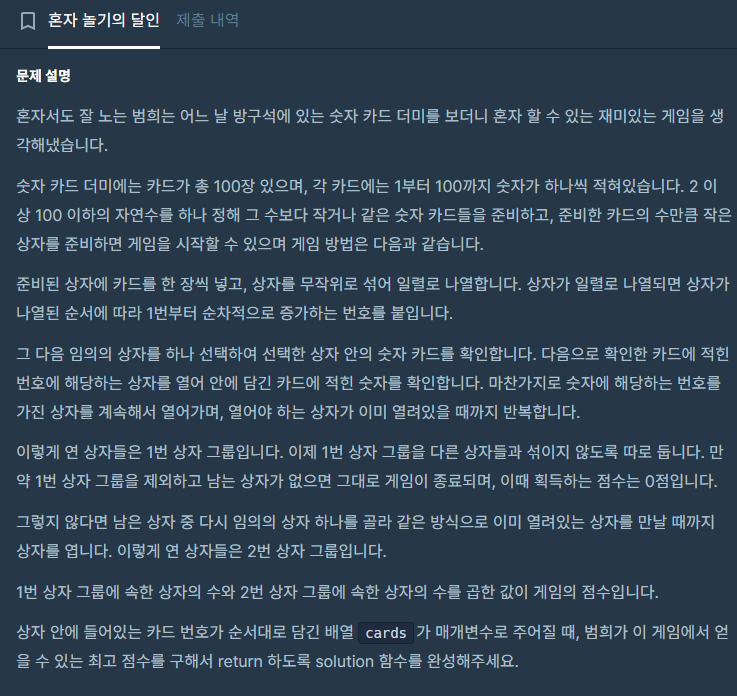
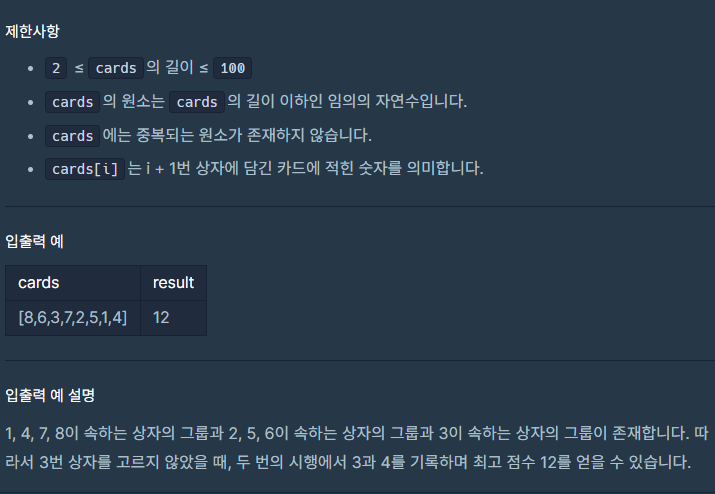
조합을 통해 키를 조합한 후 이에 대한 유일성과 최소성을 만족시키는 값을 찾아야한다.
유일성 : 유일한 값
최소성 : 여러 속성을 조합해 만든 키가 유일성을 가질 때, 한 속성을 제외해도 유일성이 유지되면 최소성을 만족하지 않는다.
어떻게 검사할까 찾아보다가 비트마스크 방법으로 조합과 유일성 최소성 검사를 하는게 직관적이라는 것을 알게 되었다.
조합
각 열을 하나의 비트로 나타내면, 비트마스크의 각 비트는 열의 포함 여부를 나타낼 수 있다.
예를 들어, 열이 3개인 경우:
- 000: 아무 열도 포함하지 않음
- 001: 첫 번째 열만 포함
- 010: 두 번째 열만 포함
- 011: 첫 번째와 두 번째 열 포함
- 100: 세 번째 열만 포함
- 101: 첫 번째와 세 번째 열 포함
- 110: 두 번째와 세 번째 열 포함
- 111: 모든 열 포함
이런식으로 표현할 수 있다.
이 방법을 통해 조합을 생성하려면 2^열의 수로 순회하면 된다.
조합
// 모든 가능한 속성 조합을 생성
for (int comb = 1; comb < (1 << columns); comb++) {
// 유일성과 최소성 검사
if (isUnique(relation, columns, comb) && isMinimal(comb, candidateKeys)) {
// 유일성과 최소성을 만족하는 경우 후보키로 추가
candidateKeys.push_back(comb);
}
}
유일성 검사
유일성 검사또한 비트마스크를 통해 열 포함여부를 검사해준다.
// 유일성을 검사하는 함수
bool isUnique(vector<vector<string>>& relation, int columns, int comb) {
set<string> uniqueCheck;
for (int i = 0; i < relation.size(); i++) {
string key = "";
for (int j = 0; j < columns; j++) {
// comb의 각 비트를 확인하여 해당 열을 포함하는지 검사
if (comb & (1 << j)) {
key += relation[i][j] + " ";
}
}
// 유일성 검사: 이미 존재하는 키라면 false 반환
if (uniqueCheck.find(key) != uniqueCheck.end()) {
return false;
}
uniqueCheck.insert(key);
}
return true;
}
이때 직접적인 검사는 if (comb & (1 << j)) 부분에서 이루어진다.
comb & (1 << j) 이 부분에서 어떻게 계산이 이루어지는지는 예시를 통해 알아보자
- comb의 j번째 비트가 1인지 검사하려면, 1 << j를 사용하여 j번째 비트만 1인 숫자를 만든다.
- comb & (1 << j)를 수행하면, comb의 j번째 비트가 1일 때만 결과가 1이 됩니다. 그렇지 않으면 결과가 0이 된다.
- comb = 5 (0101)
- 열의 개수 columns = 4
- j = 0:
- 1 << 0는 0001
- comb & 0001은 0101 & 0001이므로 결과는 0001 (참)
- j= 1:
- 1 << 1은 0010
- comb & 0010은 0101 & 0010이므로 결과는 0000 (거짓)
- j = 2:
- 1 << 2은 0100
- comb & 0100은 0101 & 0100이므로 결과는 0100 (참)
- j = 3:
- 1 << 3은 1000
- comb & 1000은 0101 & 1000이므로 결과는 0000 (거짓)
j = 0과 j = 2에서 조건이 참이므로, 첫 번째와 세 번째 열의 값이 key에 추가
최소성 검사
기존 후보키로 만들어진 것이 현재 조합의 부분집합에 포함된다면 후보키가 아니다.
// 최소성을 검사하는 함수
bool isMinimal(int comb, vector<int>& candidateKeys) {
// 기존의 후보키들에 대해 검사
for (int key : candidateKeys) {
// 기존의 후보키가 현재 조합에 포함되는지 검사
if ((comb & key) == key) {
// 기존 후보키가 현재 조합의 부분집합이면 최소성 만족하지 않음
return false;
}
}
// 모든 기존 후보키가 현재 조합의 부분집합이 아니면 최소성 만족
return true;
}
전체코드
#include <iostream>
#include <vector>
#include <string>
#include <set>
using namespace std;
// 유일성을 검사하는 함수
bool isUnique(vector<vector<string>>& relation, int columns, int comb) {
set<string> uniqueCheck;
// 각 튜플(행)에 대해 검사
for (int i = 0; i < relation.size(); i++) {
string key = "";
// comb의 각 비트를 확인하여 해당 열을 포함하는지 검사
for (int j = 0; j < columns; j++) {
if (comb & (1 << j)) {
// comb의 j번째 비트가 1이면 해당 열을 key에 추가
key += relation[i][j] + " ";
}
}
// 유일성 검사: 이미 존재하는 키라면 false 반환
if (uniqueCheck.find(key) != uniqueCheck.end()) {
return false;
}
// 새로운 키를 set에 추가
uniqueCheck.insert(key);
}
// 모든 튜플에 대해 유일성을 만족하면 true 반환
return true;
}
// 최소성을 검사하는 함수
bool isMinimal(int comb, vector<int>& candidateKeys) {
// 기존의 후보키들에 대해 검사
for (int key : candidateKeys) {
// 기존의 후보키가 현재 조합에 포함되는지 검사
if ((comb & key) == key) {
// 기존 후보키가 현재 조합의 부분집합이면 최소성 만족하지 않음
return false;
}
}
// 모든 기존 후보키가 현재 조합의 부분집합이 아니면 최소성 만족
return true;
}
int solution(vector<vector<string>> relation) {
int rows = relation.size(); // 튜플(행)의 개수
int columns = relation[0].size(); // 속성(열)의 개수
vector<int> candidateKeys; // 후보키를 저장할 벡터
// 모든 가능한 속성 조합을 생성
for (int comb = 1; comb < (1 << columns); comb++) {
// 유일성과 최소성 검사
if (isUnique(relation, columns, comb) && isMinimal(comb, candidateKeys)) {
// 유일성과 최소성을 만족하는 경우 후보키로 추가
candidateKeys.push_back(comb);
}
}
// 후보키의 개수 반환
return candidateKeys.size();
}
int main() {
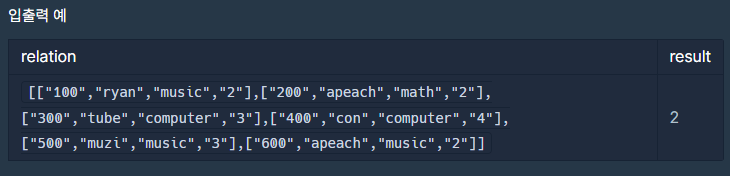
vector<vector<string>> relation = {
{"100", "ryan", "music", "2"},
{"200", "apeach", "math", "2"},
{"300", "tube", "computer", "3"},
{"400", "con", "computer", "4"},
{"500", "muzi", "music", "3"},
{"600", "apeach", "music", "2"}
};
cout << solution(relation) << endl; // 출력: 2
return 0;
}
'코딩테스트 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스][LV2][C++]이모티콘 할인행사 (0) | 2024.07.01 |
|---|---|
| [프로그래머스][LV2][C++]혼자 놀기의 달인 (0) | 2024.06.28 |
| [프로그래머스][LV2][C++]두원 사이의 정수 (0) | 2024.06.27 |
| [프로그래머스][LV2][C++]과제 진행하기 (0) | 2024.06.26 |
| [프로그래머스][LV2][C++]점 찍기 (0) | 2024.06.24 |