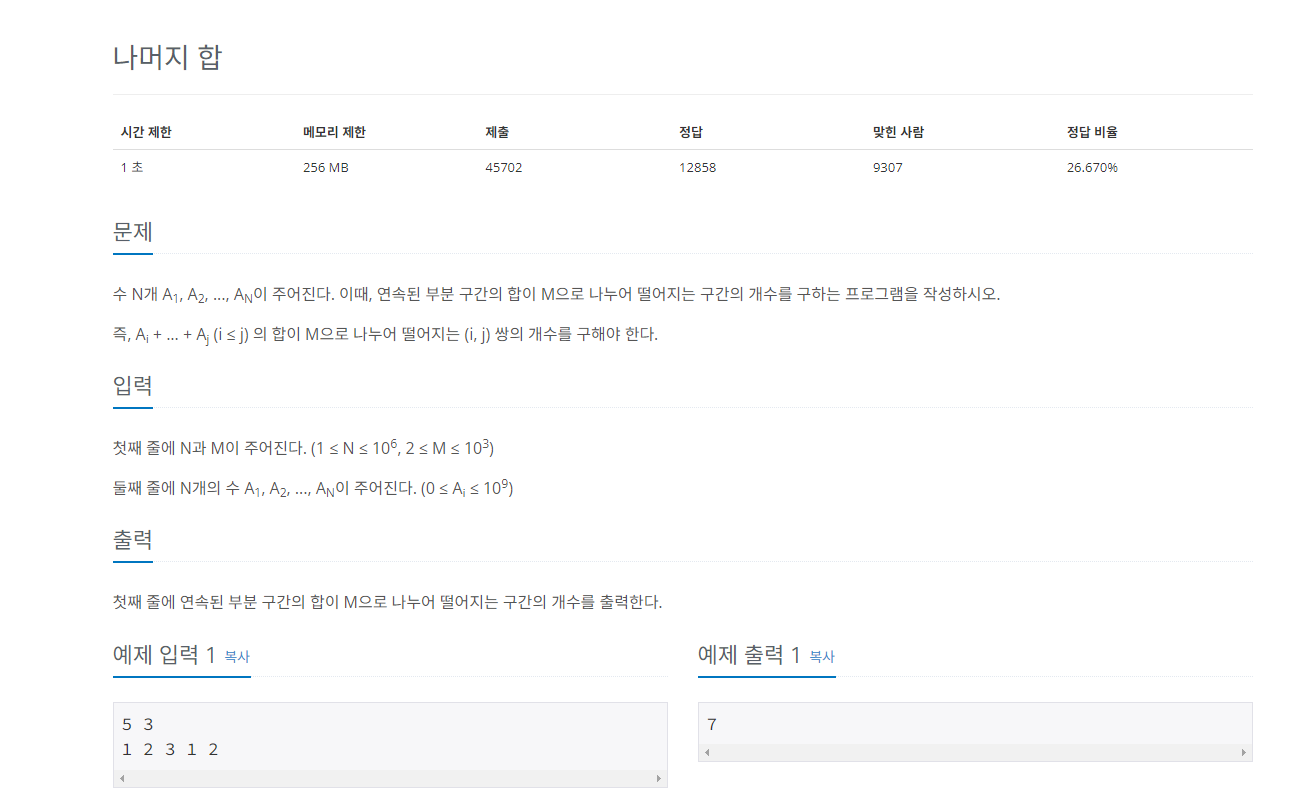
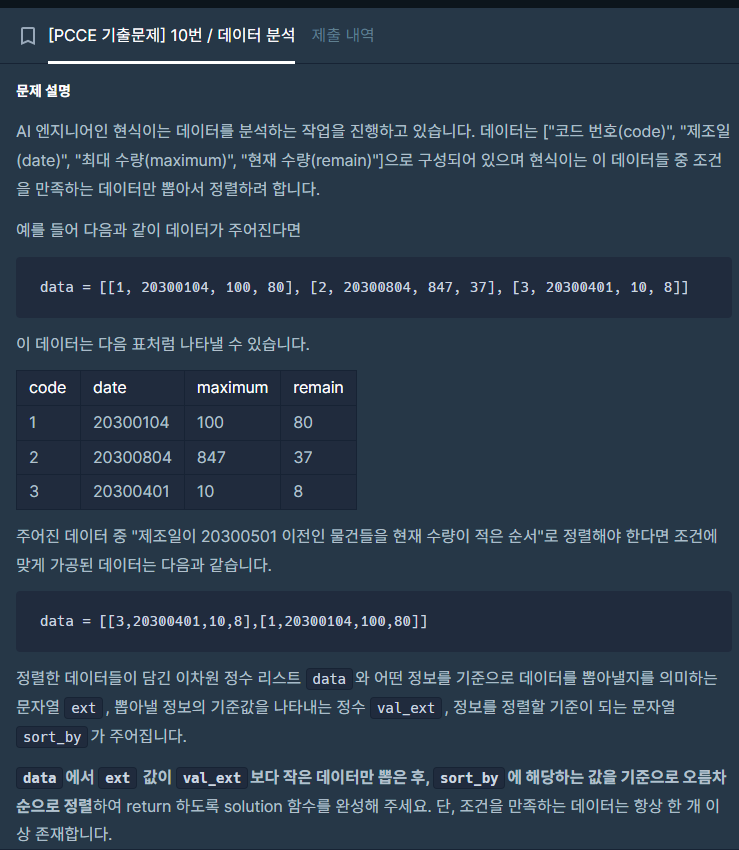
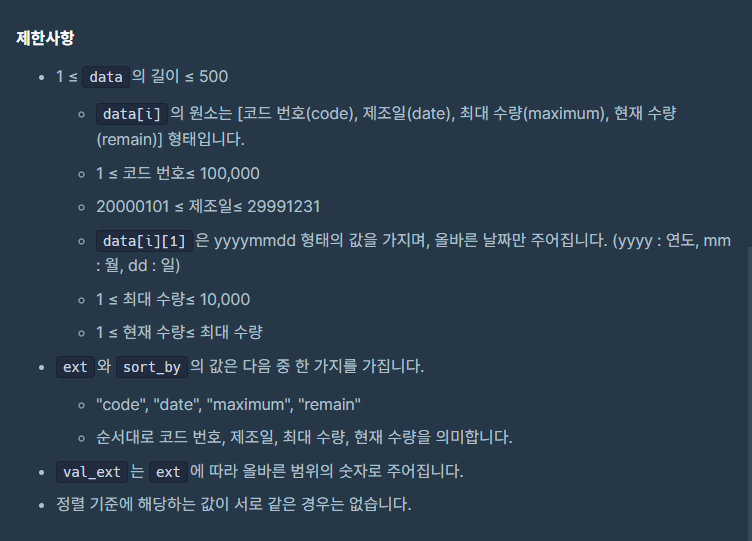
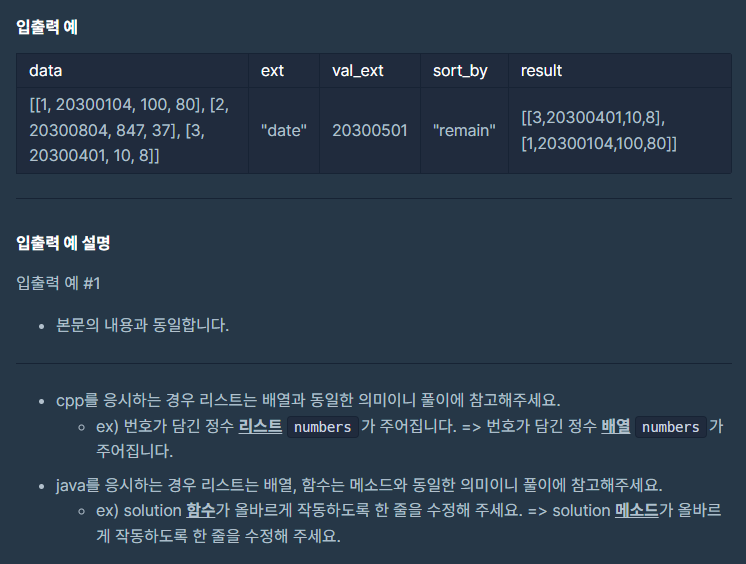
투 포인터
투 포인터는 2개의 포인터로 문제를 푸는 것으로 즉, 가르키는 값을 2개로 둬서 문제를 푸는 방법이다.
투 포인터는 2개의 값을 통해 나올 수 있는 경우의 수와 기준 값 즉 문제에서 요구하는 바에 따라 이동원칙을 만들고 이에 따라 코드로 구현하는 것이 핵심이다.
예시 1. 좋은 수 구하기
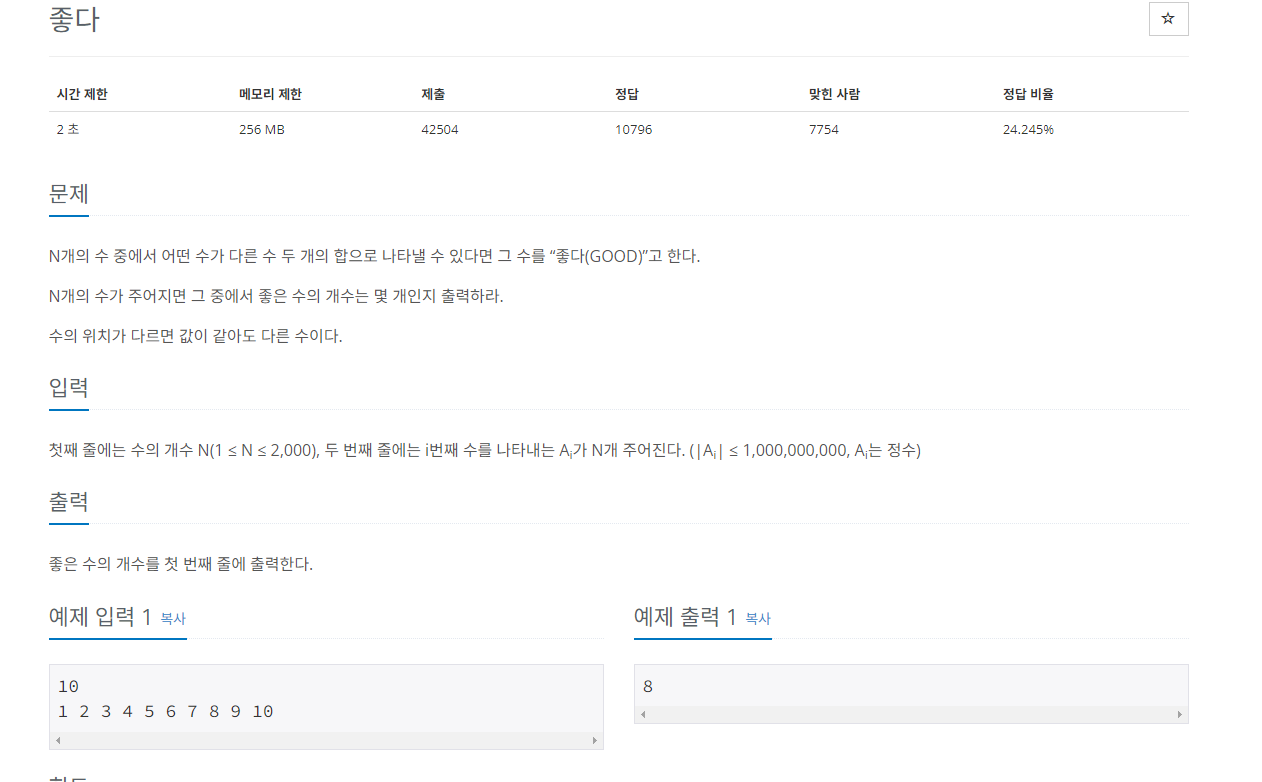
이 문제는 수를 입력받아 배열을 만들고 정렬한 후 양쪽 끝에 투 포인터 i,j를 위치시키고 이동원칙을 만든 후 탐색을 수행하면 된다.
좋은 수를 K라고 했을 때 K이면 좋은 수이고 이것을 구하는 이동원칙을 구하면 된다.
이동원칙(가정 i<j )
1. A[i]+A[j] >K -> j-- 2. A[i]+A[j}<K i++ 3. A[i]+A[j] ==k count++ break;
또한 정렬된 데이터에서 좋은 수를 만들 떄, 자기자신은 포함 시키면 안된다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N;
cin >> N;
vector<int>A(N, 0);
for (int i = 0; i < N; i++) {
cin >> A[i];
}
sort(A.begin(), A.end());
int Result = 0;
for (int k = 0; k < N; k++) {
long find = A[k];
int i = 0;
int j = N - 1;
while (i < j) {
if (A[i] + A[j] == find) {
if (i != k && j != k) {
Result++;
break;
}
else if (i == k) {
i++;
}
else if (j == k) {
j--;
}
}
else if (A[i] + A[j] < find) {
i++;
}
else {
j--;
}
}
}
cout << Result << "\n";
}
※슬라이딩 윈도우
배열을 이동하면서 구한 부분 배열의 값을 업데이트 해주고 이에 따라 문제에서 주어진 조건을 확인하며 문제를 푸는 것이다.
예시 문제
최솟값찾기 1
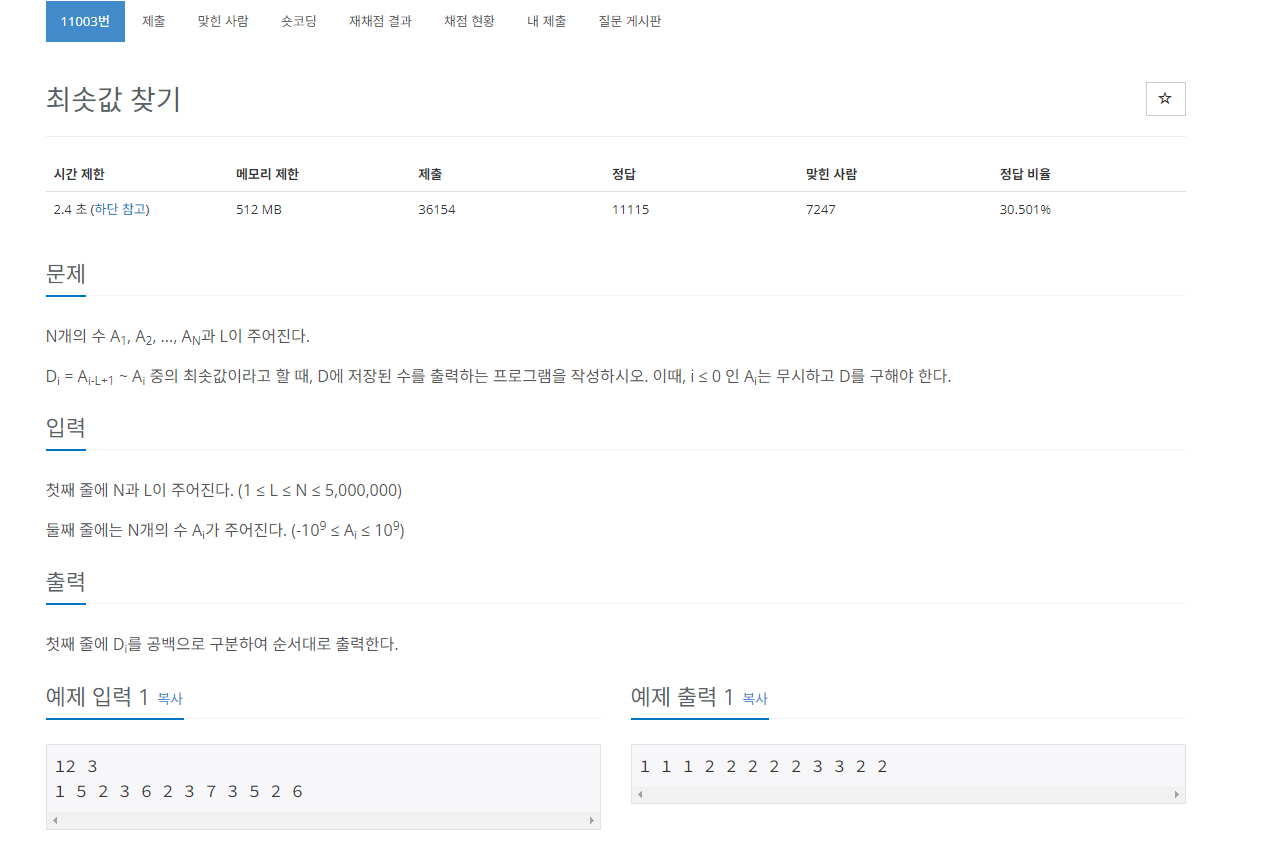
이 문제에서는 부분 배열에서 최솟값을 구하는 것인데 최솟값을 구하는 범위가 i-L+1~ i 로 길이가 L인 부분 배열이다.
이 때, n과 l의 최대 범위가 5,000,000이여서 O(nlogn)인 정렬을 사용할 수 가 없다. 그래서 이 문제에서는 슬라이딩 윈도우를 덱으로 구현하여 정렬효과를 볼 수 있다.
deque<pair<int,int> mydeque; 라고 했을 때 숫자 값 , 인덱스 순서로 값을 넣어주고
현재값이 기존값보다 크다면 뒤에 넣어주고 만약 끝 인덱스- 주어진 부분배열 크기 했을 때, 처음 인덱스보다 크거나 같다면 처음값을 빼준다
현재값이 기존값보다 작다면 기존값을 삭제하고 넣어준다.
이렇게 되면 덱에서 제일 첫번째에 있는 값이 부분배열의 최솟값이 된다.
#include <iostream>
#include <deque>
using namespace std;
typedef pair<int, int> Node;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N, L;
cin >> N>>L;
deque<Node> dq;
for (int i = 0; i < N; i++) {
int now;
cin >> now;
while (dq.size() && dq.back().first > now) {
dq.pop_back();
}
dq.push_back(Node(now, i));
if (dq.front().second <= i - L) {
dq.pop_front();
}
cout << dq.front().first << ' ';
}
}'코딩테스트 > 이론' 카테고리의 다른 글
| [코딩테스트][C++]이론5. DFS 와 BFS (0) | 2024.03.29 |
|---|---|
| [코딩테스트][C++]이론4-2. 정렬 (2) | 2024.03.16 |
| [코딩테스트][C++]이론4-1. 정렬 (0) | 2024.03.15 |
| [코딩테스트][C++]이론3. 스택과 큐 (0) | 2024.03.14 |
| [코딩테스트][C++]이론1. 구간 합 (3) | 2024.03.12 |