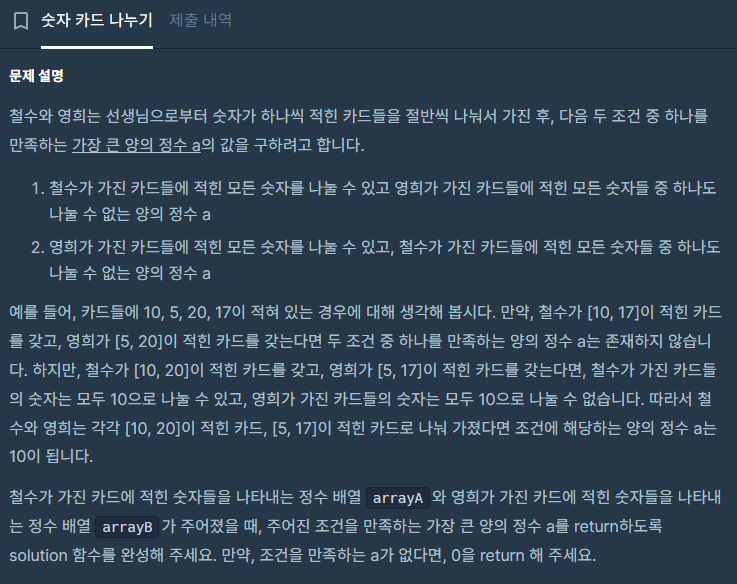
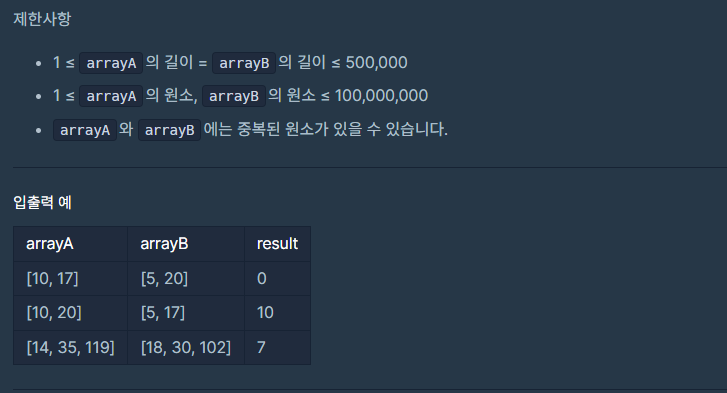
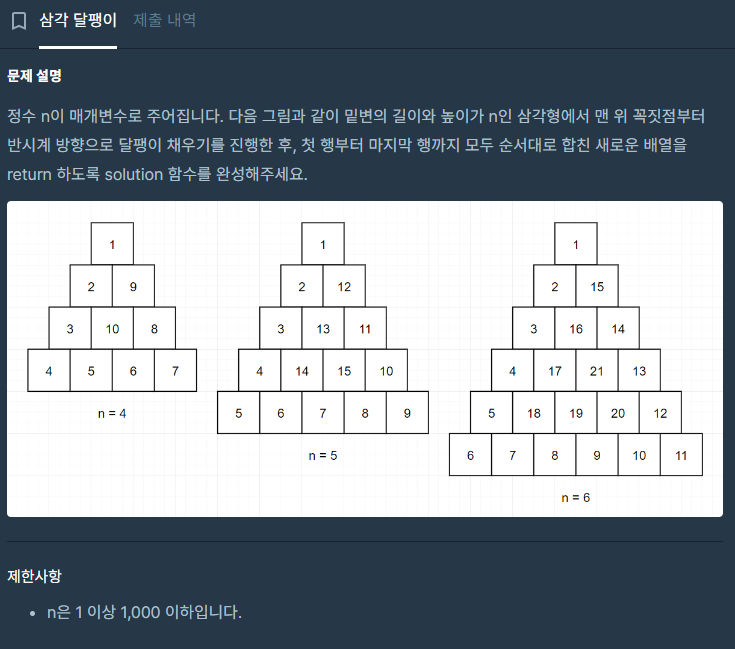
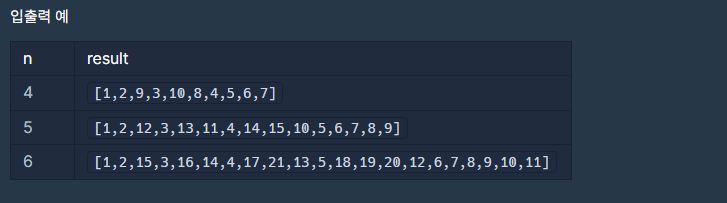
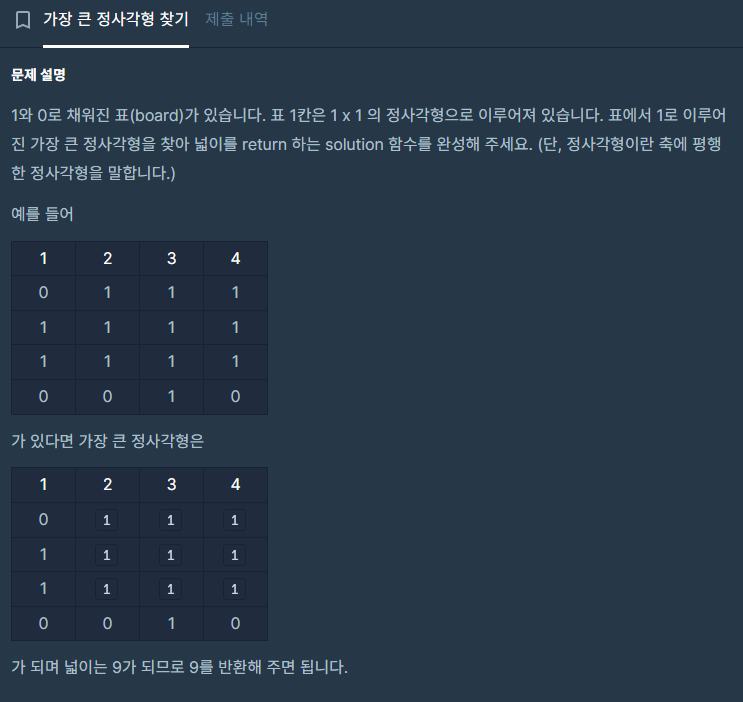
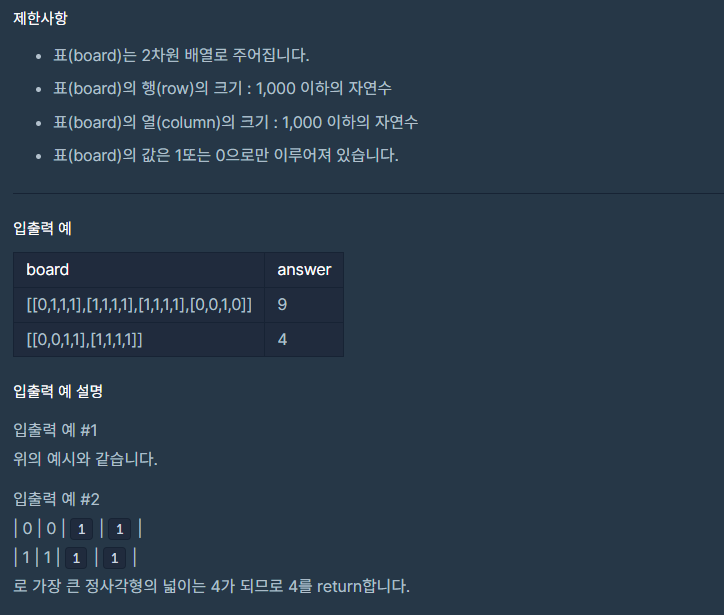
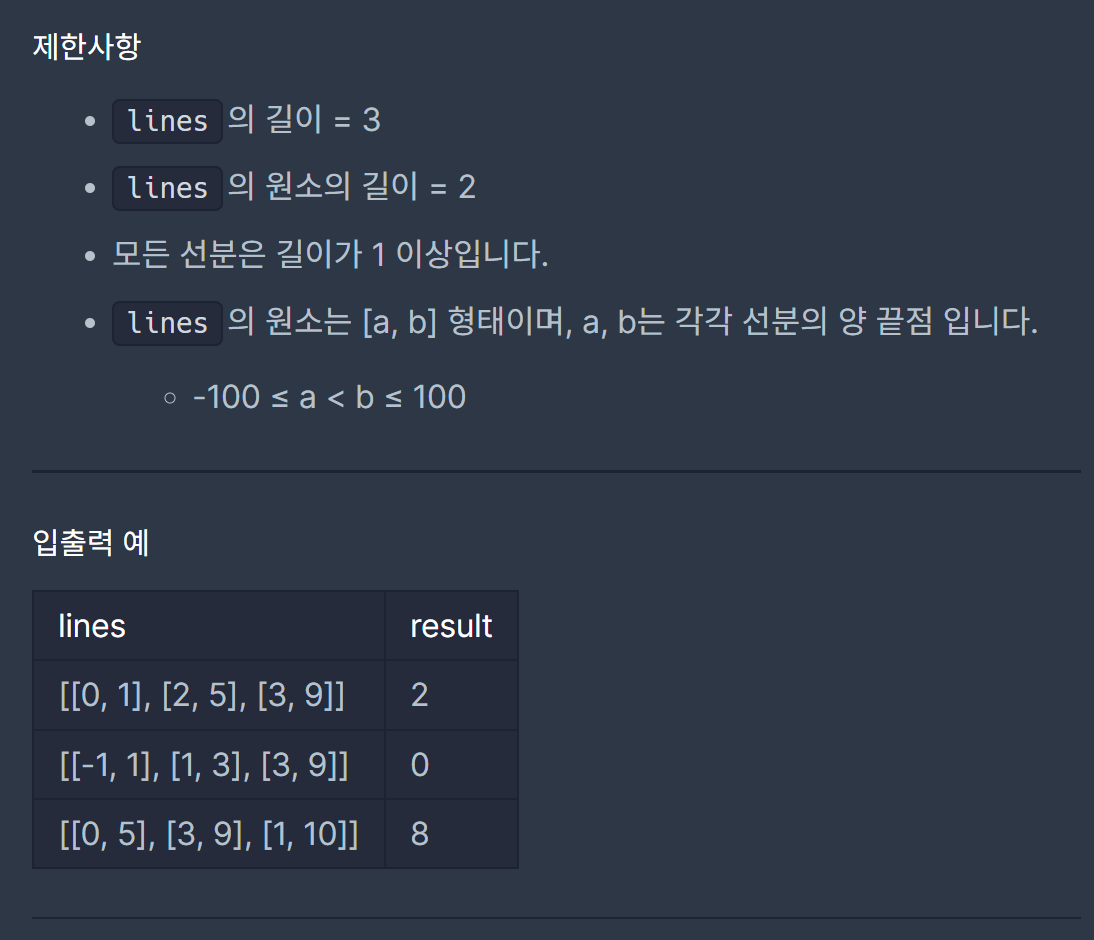
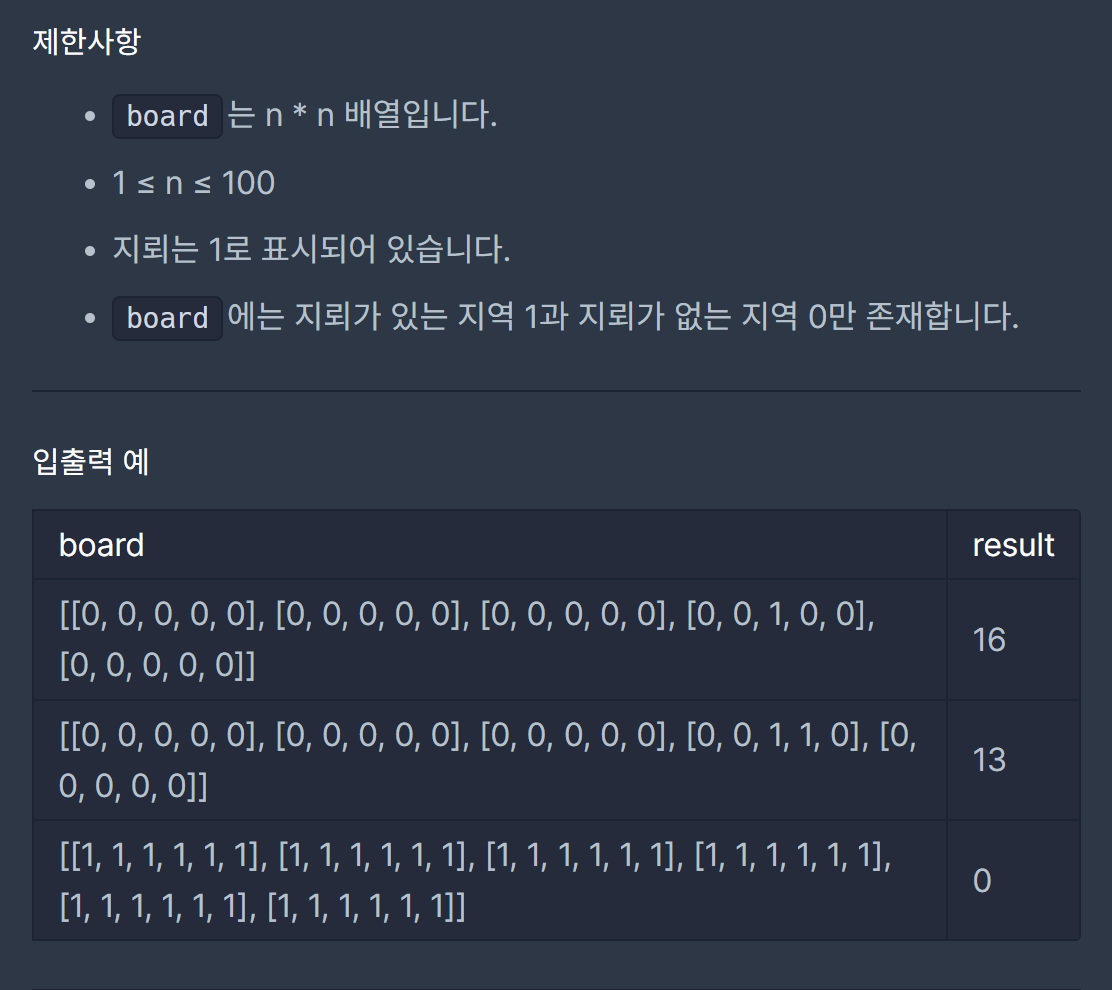
설명이 긴데 잘 읽어보면 핵심은 한 그룹의 최대공약수로 다른 그룹의 모든 수를 나눌 수 없는 값을 찾는 것이다 만약 그룹 별로 조건을 만족하는 값이 하나씩 나온다면 그 중 큰 값을 정답으로 한다.
#include <string>
#include <vector>
#include <algorithm>
//핵심 : 한그룹의 최대공약수로 다른 그룹을 나눴을 때 안 나눠지는게 있는가
using namespace std;
int gcd(int a, int b) { //최대공약수 구하기
if (b == 0) return a;
return gcd(b, a % b);
}
int solution(vector<int> arrayA, vector<int> arrayB) {
int answer = 0;
int cur = arrayA[0];
for (int i = 1; i < arrayA.size(); i++) {
cur = gcd(cur, arrayA[i]);
if (cur == 1) break;
}
if (cur != 1) {
int cnt;
for (cnt = 0; cnt < arrayB.size(); cnt++) {
if (arrayB[cnt] % cur == 0) break;
}
if (cnt == arrayB.size()) answer = cur;
}
cur = arrayB[0];
for (int i = 1; i < arrayB.size(); i++) {
cur = gcd(cur, arrayB[i]);
if (cur == 1) break;
}
if (cur != 1) {
int cnt;
for (cnt = 0; cnt < arrayA.size(); cnt++) {
if (arrayA[cnt] % cur == 0) break;
}
if (cnt == arrayA.size()) answer = max(cur, answer); //만약 두 그룹 다 조건에 만족하는 수가 있다면 그 중에 큰 수가 정답
}
return answer;
}
그리디 알고리즘은 현재 상태에서 보는 선택지 중 최선의 선택지를 선택하는 것이 전체의 선택지에서 최선의 선택지를 선택하는 것이라고 가정하는 알고리즘이다.
수행과정
1. 최선의 해 선택 : 현재 상태에서 가장 최선이라고 생각되는 해를 선택한다.
2. 적절성 검사 : 현재 선택한 해가 전체 문제에서 적절한지 검사
3. 해 검사 : 현재 상태에서 최선의 선택지가 전체 문제에서의 최선인지 검사
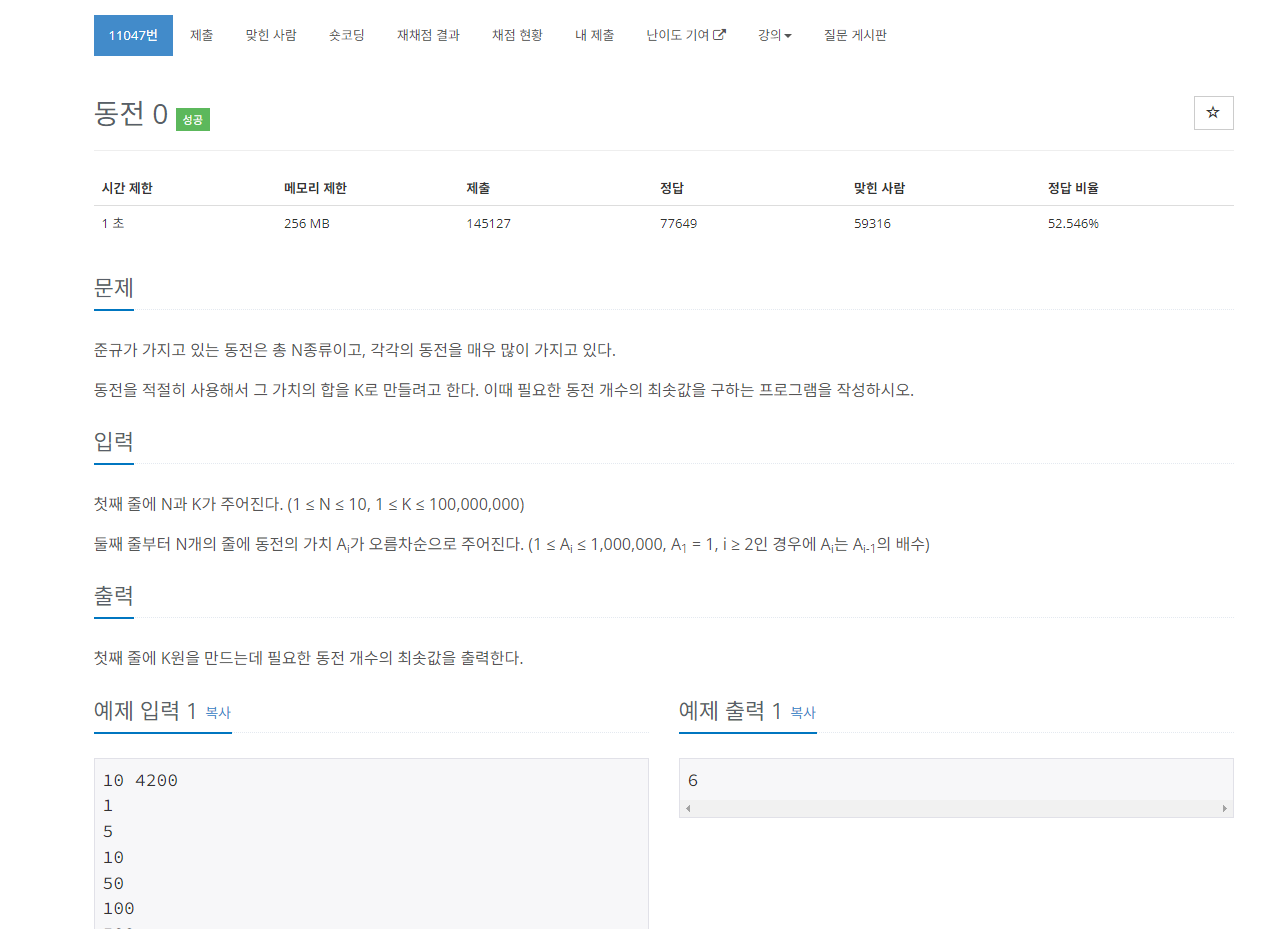
예시 문제1.
동전개수의 최솟값 구하기
문제에서 그리디하게 접근해보자면 가장 가격이 큰 동전부터 사용하면 동전개수를 최소로 사용할 수 있다.
#include <iostream>
#include <vector>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n, k;
cin >> n >> k;
vector<int> a(n);
for (int i = 0; i < n; i++) {
cin >> a[i];
}
int cnt = 0;
for (int i = n - 1; i >= 0; i--) {
cnt += k / a[i];
k %= a[i];
}
cout << cnt << "\n";
}
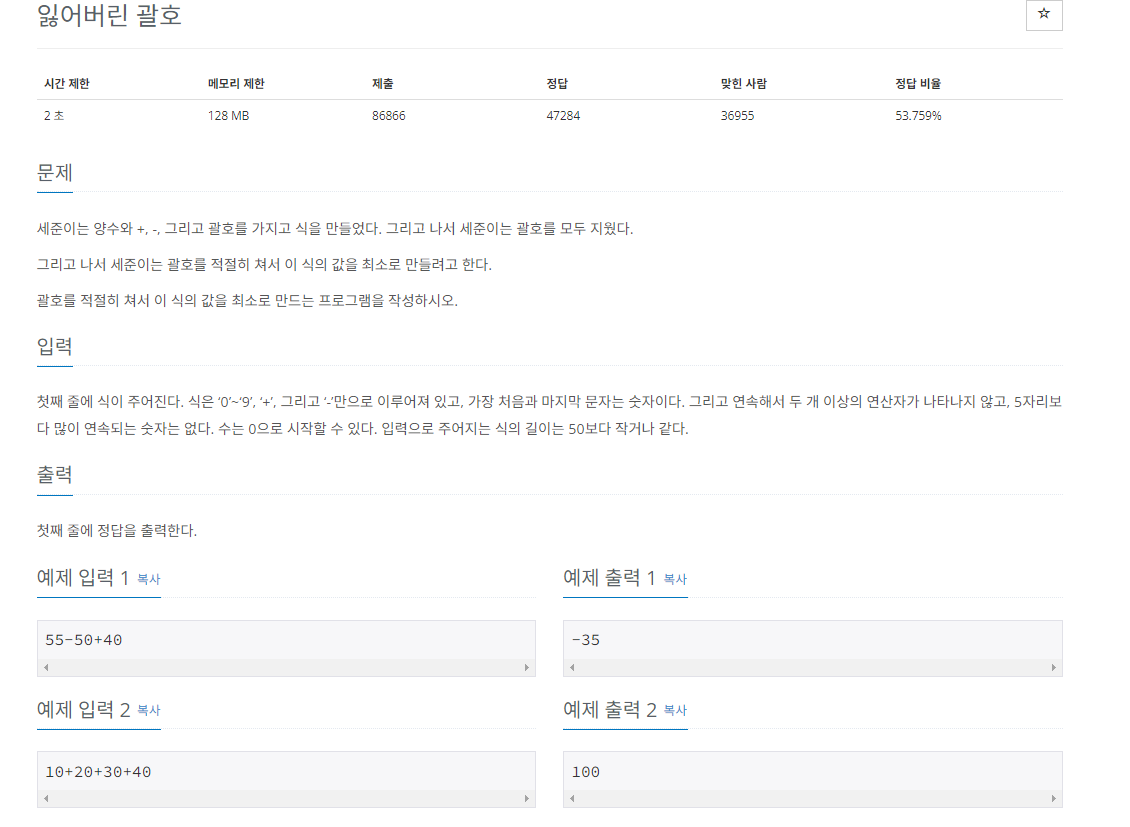
문제 예시2
최솟값을 만드는 괄호배치 찾기
최솟값을 만들려면 가능한 큰 수를 빼야하는데 이렇게 하려면 더할걸 모두 다 더하고 빼기를 할 수 있도록 괄호를 구성해줘야한다.
#include <iostream>
#include <vector>
#include <sstream>
#include <string>
using namespace std;
vector<string> split(string input, char del);
int mySum(string a);
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int answer = 0;
string ex;
cin >> ex;
vector<string> s = split(ex, '-');
for (int i = 0; i < s.size(); i++) {
int tmp = mySum(s[i]);
if (i == 0) { //젤 앞에꺼면 더하고
answer += tmp;
}
else { //아니면 빼주기
answer -= tmp;
}
}
cout << answer << "\n";
}
vector<string> split(string input, char del) {
vector<string> result;
stringstream mystream(input);
string splitdata;
while (getline(mystream, splitdata, del)) { //split
result.push_back(splitdata);
}
return result;
}
int mySum(string a) { //-하기 전 더하기
int sum = 0;
vector<string> tmp = split(a, '+');
for (int i = 0; i < tmp.size(); i++) {
sum += stoi(tmp[i]);
}
return sum;
}
퀵정렬은 기준값(pivot)을 선정해 해당 값보다 작은 데이터를 왼쪽에 큰 데이터를 오른쪽에 분류하는 것을 반복해 정렬한다.
문제 예시1.
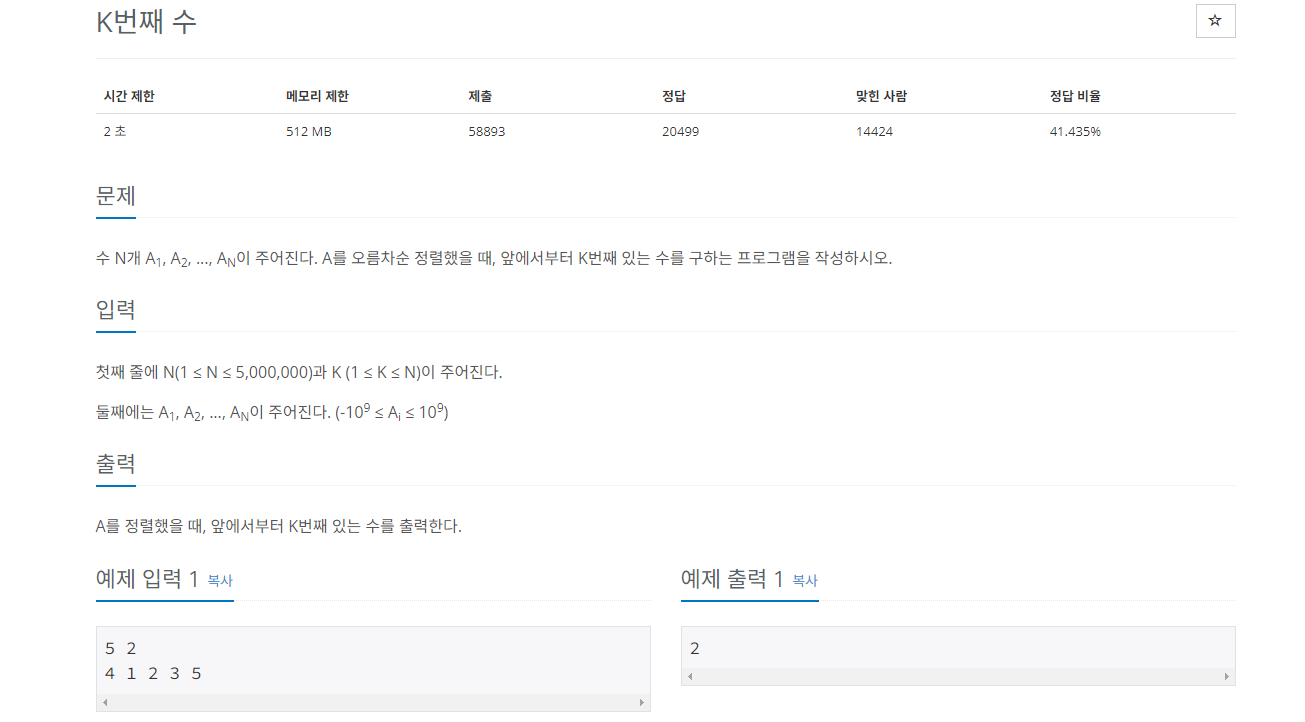
K번째 수 구하기
내장함수를 통해서 정렬할 수 도 있지만 퀵정렬의 원리를 이해하기위해 퀵정렬로 풀어보려고 한다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void quickSort(vector<int>& A, int S, int E, int K);
int partition(vector<int>& A, int S, int E);
void swap(vector<int>& A, int i, int j);
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N, K;
cin >> N >> K;
vector<int> A(N, 0);
for (int i = 0; i < N; i++) {
cin >> A[i];
}
quickSort(A, 0, N - 1, K - 1);
cout << A[K - 1];
}
void quickSort(vector<int>& A, int S, int E, int K) {
int pivot = partition(A, S, E);
if (pivot == K)
return;
else if (K < pivot)
quickSort(A, S, pivot - 1, K);
else
quickSort(A, pivot + 1, E, K);
}
int partition(vector<int>& A, int S, int E) {
if (S + 1 == E) {
if (A[S] > A[E])swap(A, S, E);
return E;
}
int M = (S + E) / 2;
swap(A, S, M);
int pivot = A[S];
int i = S + 1, j = E;
while (i <= j) {
while (j >= S + 1 && pivot < A[j]) {
j--;
}
while (i <= E && pivot > A[i]) {
i++;
}
if (i < j) {
swap(A, i++, j--); // 찾은 i와 j를 교환하기
}
else {
break;
}
}
// i == j 피벗의 값을 양쪽으로 분리한 가운데에 오도록 설정하기
A[S] = A[j];
A[j] = pivot;
return j;
}
void swap(vector<int>& A, int i, int j) {
int temp = A[i];
A[i] = A[j];
A[j] = temp;
}
2.병합정렬
병합 정렬은 divide and conquer 방식 즉 배열은 나누고 합치는 과정에서 정렬을 해주는 방식이다.
문제 예시2.
버블정렬프로그램2
n의 최대 범위가 500,000이므로 O(nlogn)의 시간복잡도로 정렬을 수행하면 된다.
하지만 제목처럼 버블정렬을 사용하면 제한 시간을 초과한다. 그런데 병합정렬의 수행과정을 보면 swap이 포함되어 있기때문에 정렬하는 과정에서 원소가 앞으로 이동한 거리만큼 더해서 그 값을 출력해주면 된다.
#include <iostream>
#include <vector>
using namespace std;
void merge_sort(int s,int e);
static vector<int> a;
static vector<int> tmp;
static long result;
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
a = vector<int>(n + 1, 0);
tmp= vector<int>(n + 1, 0);
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
result = 0;
merge_sort(1, n);
cout << result << "\n";
}
void merge_sort(int s, int e) {
if (e - s < 1) {
return;
}
int m = s + (e - s) / 2; //중앙값
merge_sort(s, m); //시작~중앙
merge_sort(m + 1, e); //중앙~끝
for (int i = s; i <= e; i++) {
tmp[i] = a[i];
}
int k = s;
int idx1 = s;
int idx2 = m + 1;
while (idx1 <= m && idx2 <= e) { //병합
if (tmp[idx1] > tmp[idx2]) {
a[k] = tmp[idx2]; //값을 작은값으로 업데이트 해주기
result += idx2 - k; //이동한 만큼 더해주기
k++;
idx2++;
}
else {
a[k] = tmp[idx1];
k++;
idx1++;
}
}
while (idx1 <= m) { //남은값 배열에 채워주기
a[k] = tmp[idx1];
k++;
idx1++;
}
while (idx2 <= e) { //남은값 배열에 채워주기
a[k] = tmp[idx2];
k++;
idx2++;
}
}
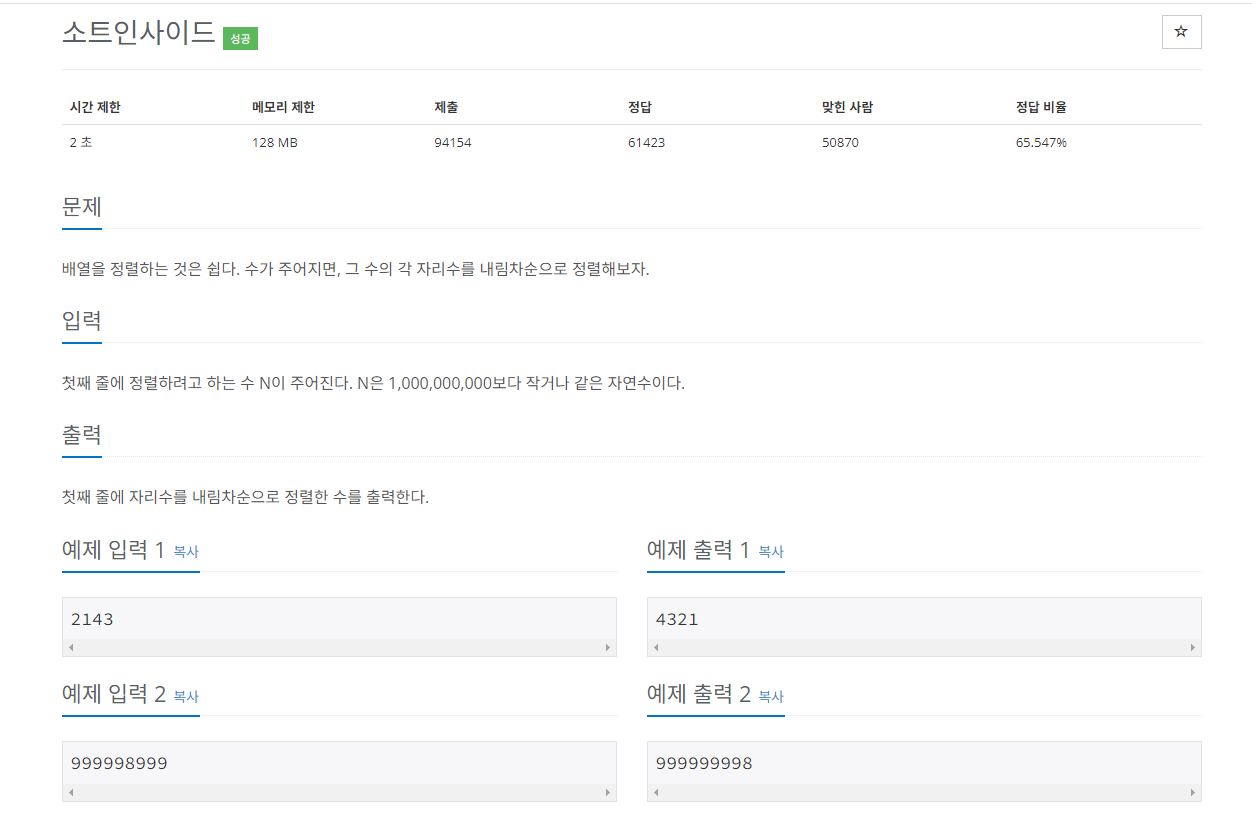
3. 기수정렬
기수정렬은 값을 비교하는 것이아니라 값을 놓고 비교할 자릿수를 정한다음 해당 자릿수만 비교하여 정렬하는 것으로
시간복잡도는 O(kn)으로 k가 데이터의 자릿수이다.
기수 정렬은 값의 자릿수를 대표하는 10개의 큐를 사용한다.
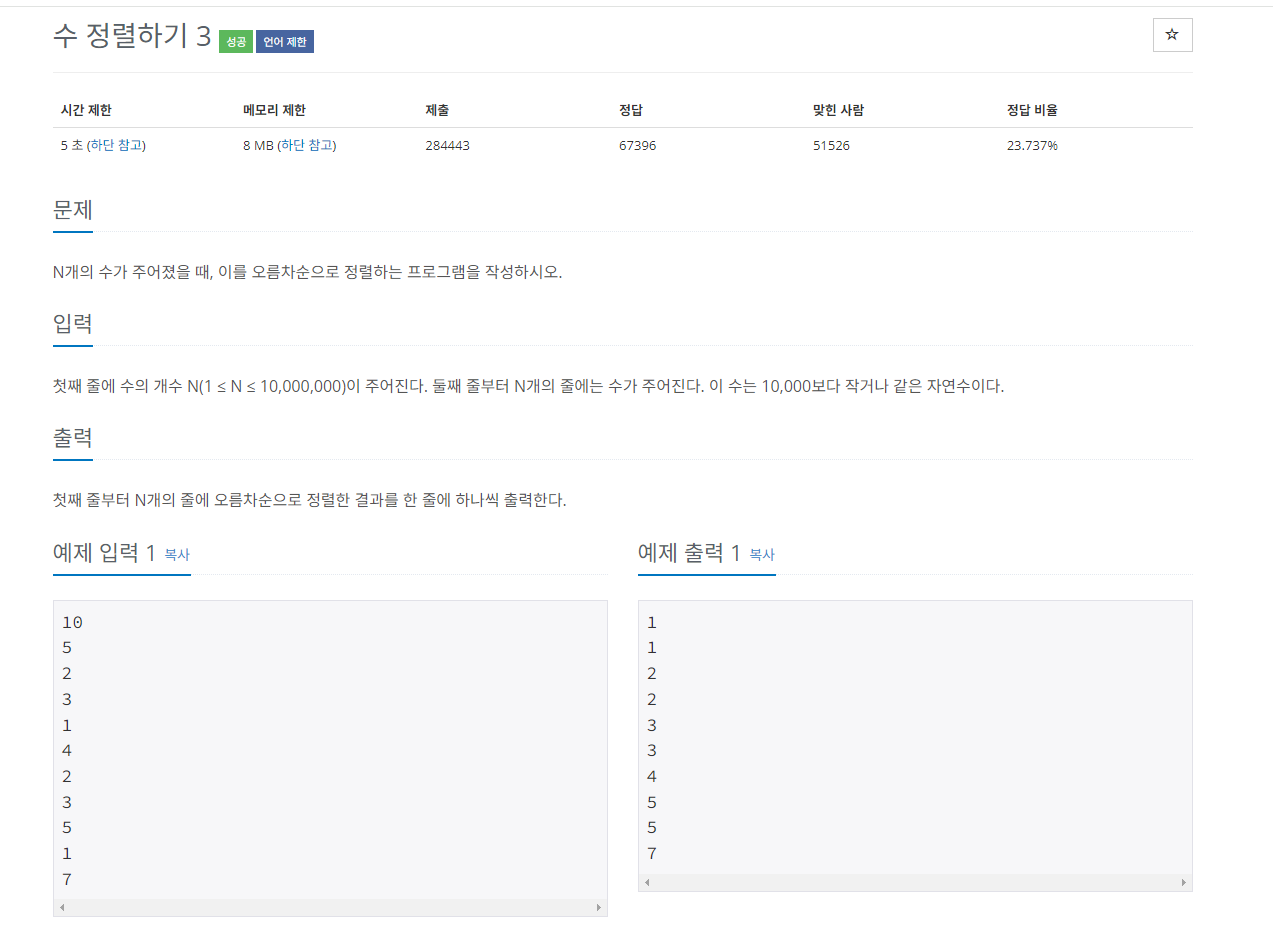
문제예시3.
수 정렬하기 3
이 문제는 n의 최대 10,000,000이 나올 수 있기 때문에 nlogn 보다 빠른 알고리즘이 필요하다. 숫자의 크기가 10,000 이하이기 때문에 기수 정렬과 함께 많이 사용되는 계수 정렬을 사용하여 문제를 풀어보려고 한다.
계수정렬은 수 값을 받아 수의 값을 인덱스 값으로 판단하고 그 인덱스에 해당하는 값을 1증가시키고 배열에 1이상인 것들을 출력시켜주면 된다.
#include <iostream>
using namespace std;
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
int cnt[10001] = { 0 };
int num = 0;
for (int i = 1; i <= n; i++) {
cin >> num;
cnt[num]++;
}
for (int i = 0; i <= 10000; i++) {
if (cnt[i] != 0) {
for (int j = 0; j < cnt[i]; j++) {
cout << i << "\n";
}
}
}
}
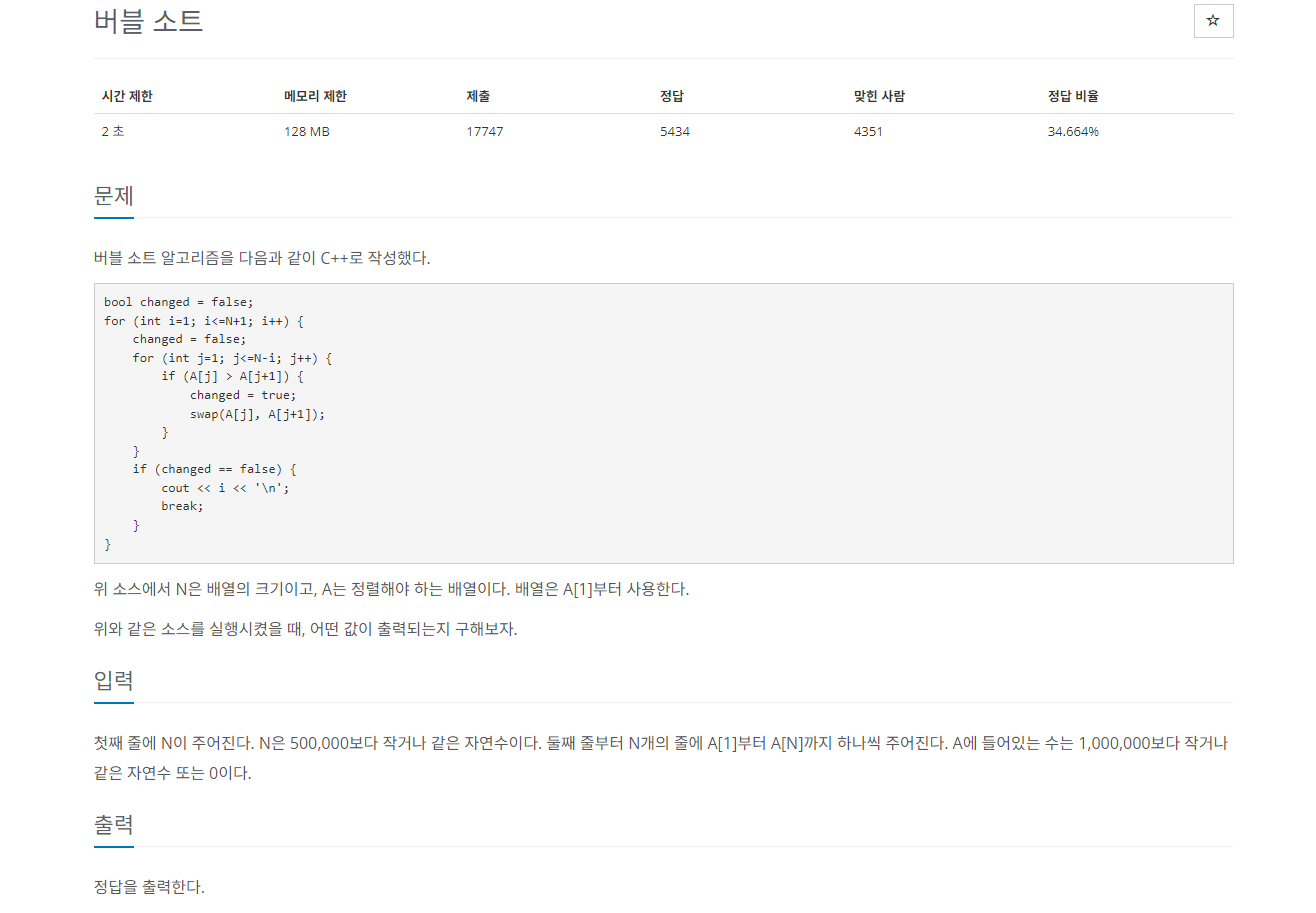
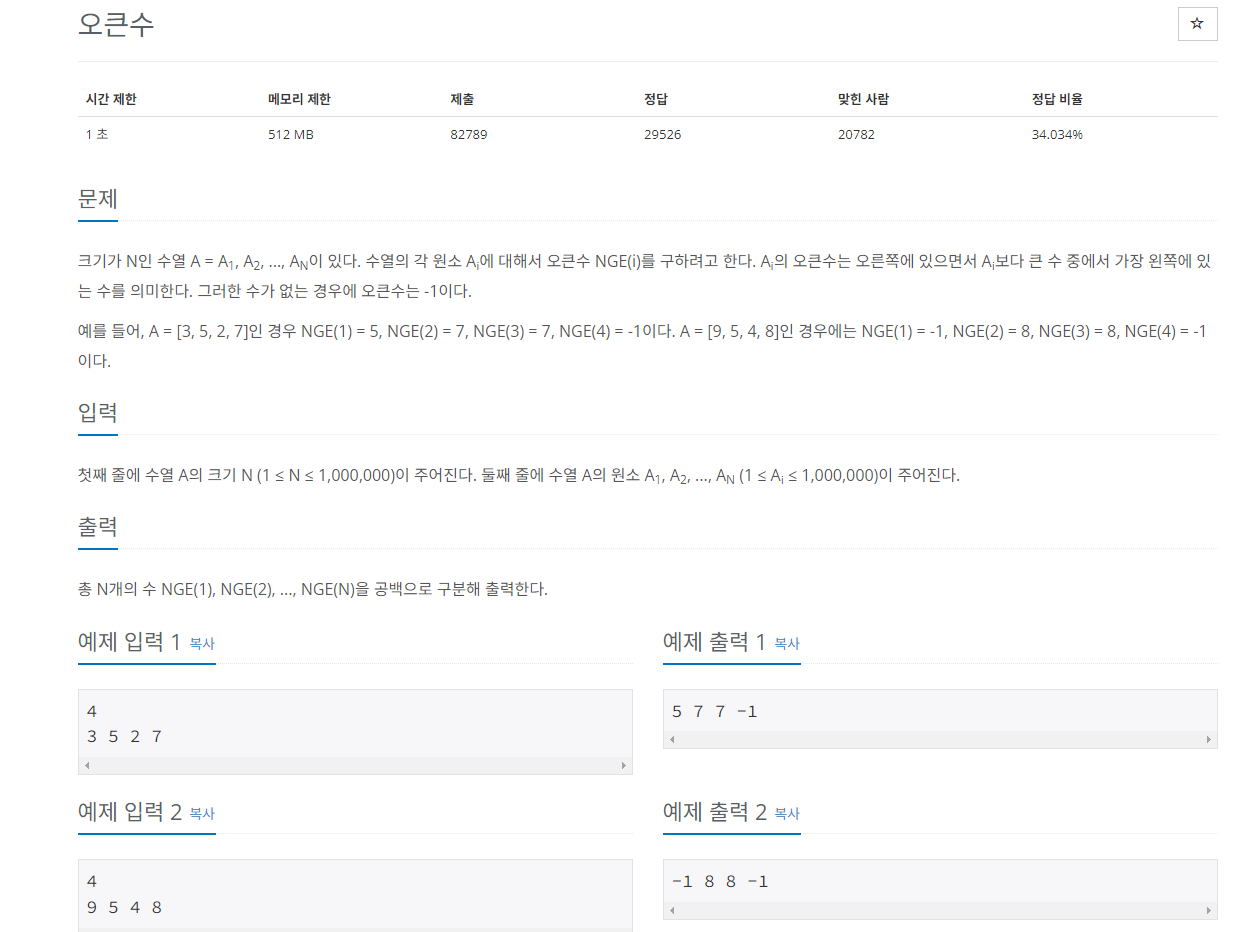
문제에서 요구하는바는 swap이 끝나고 change가 false로 유지될때의 i 값이다. for문이 몇번이나 수행됐는지 구하면 된다.
n의 최대가 500,000이기 때문에 버블정렬은 사용할 수 없다.
어떤 방법을 사용할지 생각해보자면 일단 버블정렬이 수행되는 방식에 대해 생각해보면 좋다.
버블정렬은 1~n-1까지 왼쪽에서 오른쪽으로 이동하면서 swap을 수행한다. 이는 swap할때 왼쪽으로 1칸씩만 이동할 수 있다는 것이다. 따라서 데이터 정렬하기전과 정렬 후의 index를 비교해서 가장 많이 이동한 값이 for문이 수행된 횟수가 나온다. 그리고 정렬이 끝난 후 마지막으로 for문이 돌때를 고려하여 max에 1을 더해준다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int, int> Node;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<pair<int, int>>a(n);
for (int i = 0; i < n; i++) {
cin >> a[i].first;
a[i].second = i;
}
sort(a.begin(), a.end());
int max = 0;
for (int i = 0; i < n; i++) {
if (max < a[i].second - i) {
max = a[i].second - i;
}
}
cout << max + 1;
}
2.선택 정렬
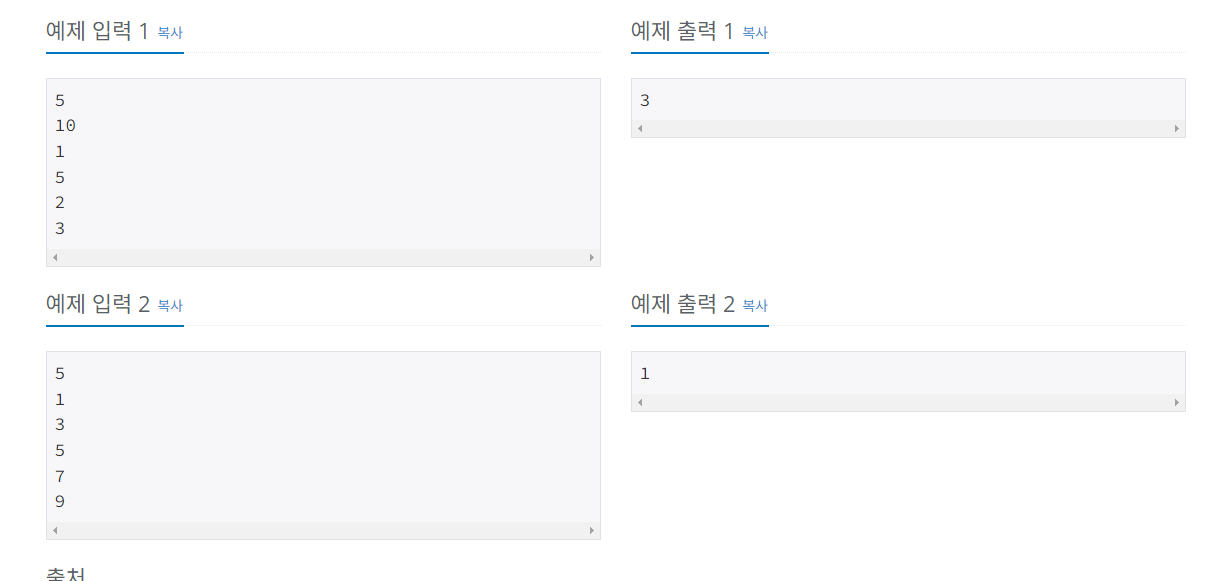
최대나 최소 데이터를 나열된 순으로 찾아가며 선택하고 그 수를 앞으로 보내면서 정렬하는 방법이다.
문제예시2.
내림차순으로 자릿수 정렬하기
내장함수를 사용해도 풀 수 있지만 n의 길이가 길지 않아서 선택정렬을 통해 풀어보아도 된다.
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
string n;
cin >> n;
vector<int>a(n.size(), 0);
for (int i = 0; i < n.size(); i++) {
a[i] = stoi(n.substr(i,1));
}
for (int i = 0; i < n.size(); i++) {
int max = i;
for (int j = i + 1; j < n.size(); j++) { //제일 큰 수 구하기
if (a[j] > a[max]) {
max = j;
}
}
if (a[i] < a[max]) {
int tmp = a[i];
a[i] = a[max];
a[max] = tmp;
}
}
for (int i = 0; i < a.size(); i++) {
cout << a[i];
}
}
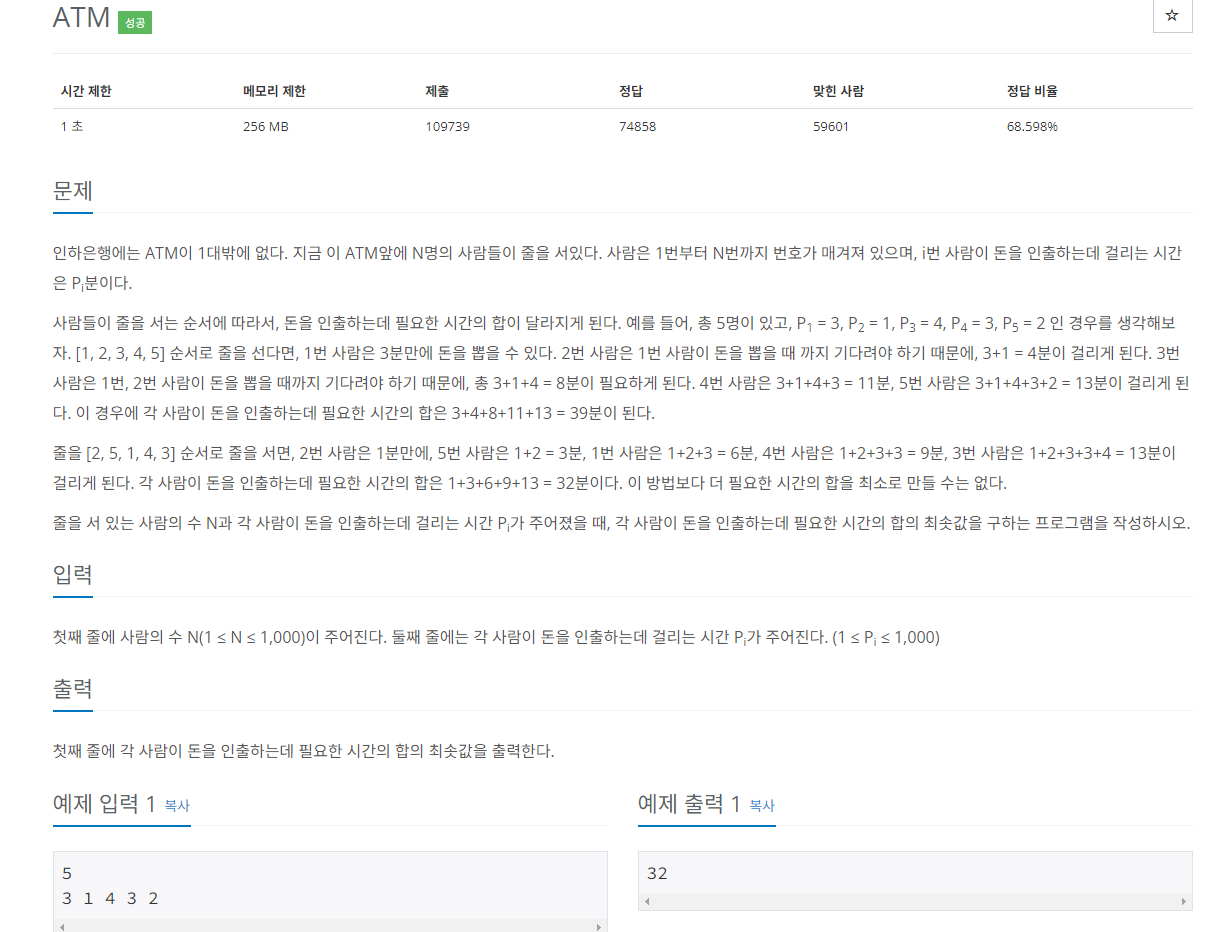
3.삽입정렬
삽입정렬은 현재 정렬된 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입하는 방식이다.
문제예시3.
ATM인출 시간 계산하기
ATM에서 모든 사람이 가장 빠른 시간에 인출하려면 시간이 가장 적게 걸리는 사람이 먼저 인출할 수 있도록 그리디하게 접근하면 된다.
그럼 오름차순으로 정렬을 하면 되는데 n의 최댓값이 1,000이고 시간제한이 1초여서 O(n^2)이하인 정렬 알고리즘이면 모두 사용 가능하다. 지금은 삽입정렬을 사용해보려고 한다.
#include <iostream>
#include <vector>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<int>a(n, 0);
vector<int>s(n, 0); //합배열
for (int i = 0; i < n; i++) {
cin >> a[i];
}
for (int i=0; i < n; i++) {
int insertval = a[i];
int insertidx = i;
for (int j = i - 1; j >= 0; j--) { //i 왼쪽을 탐색
if (a[i] > a[j]) {
insertidx = j + 1; //i가 j보다 크다면 i는 j보다 오른쪽에 있어야한다.
break;
}
if (j == 0) {
insertidx = 0;
}
}
for (int j = i; j > insertidx; j--) {
a[j] = a[j - 1]; //j~insertidx까지 값을 바꾸면서 insertidx의 값이 j로 가도록 한다.
}
a[insertidx] = insertval;
}
s[0] = a[0];
for (int i = 1; i < n; i++) {
s[i] = s[i - 1] + a[i];
}
int sum = 0;
for (int i = 0; i < n; i++) {
sum += s[i];
}
cout << sum;
}